hadoop本地环境搭建
版本:3.2.2
1.环境准备
需要安装java环境,此处不赘述
ssh 原来就有不用安装,不过,需要做免密登录,文档步骤如下
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
mac的系统下,按照流程执行之后,还是存在问题,报错如下:
ssh: connect to host localhost port 22: Connection refused
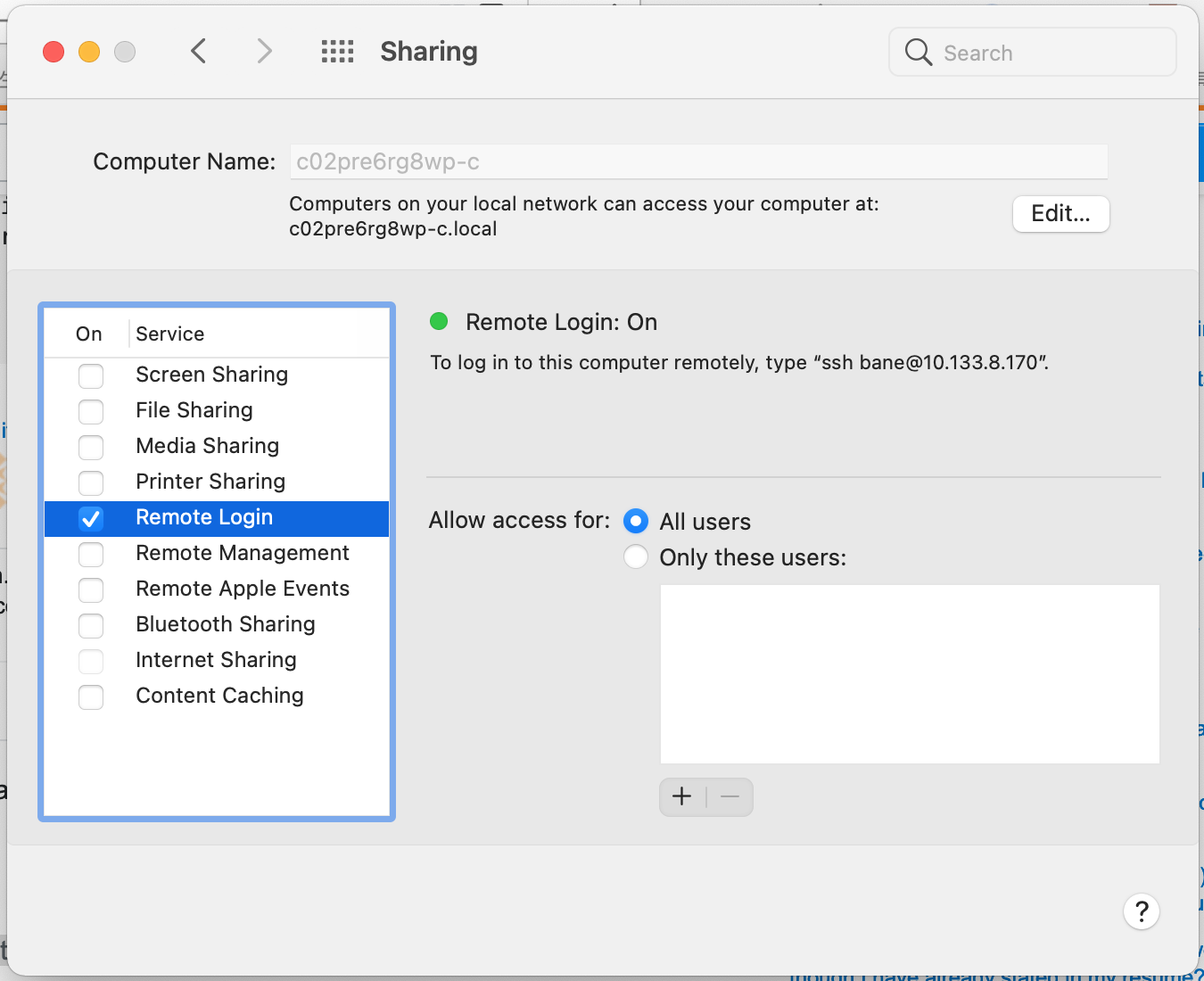
此处需要去设置运行远程登录
system preferences > sharing > remote login.
ssh localhost 成功就可以了。至此准备工作完成。
2.hadoop有三种部署方式
- 单机部署
- 伪分布式
- 分布式
2.1 单机部署
我们看单机部署,单机部署就是用系统原来的文件系统,而不是去使用hdfs。所以这里我们直接执行文件即可。在文件夹下创建一个input文件夹,然后把配置文件复制进去,跑个测试的jar包统计字符出现的次数
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*

执行 cat output/* 输出查询到的内容
1 dfsadmin
2.2 伪分布式
这个大概是我们本地部署用的最多的了。
修改配置文件
etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
执行
./bin/hdfs namenode -format
./sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [c02pre6rg8wp-c]
访问 http://localhost:9870/
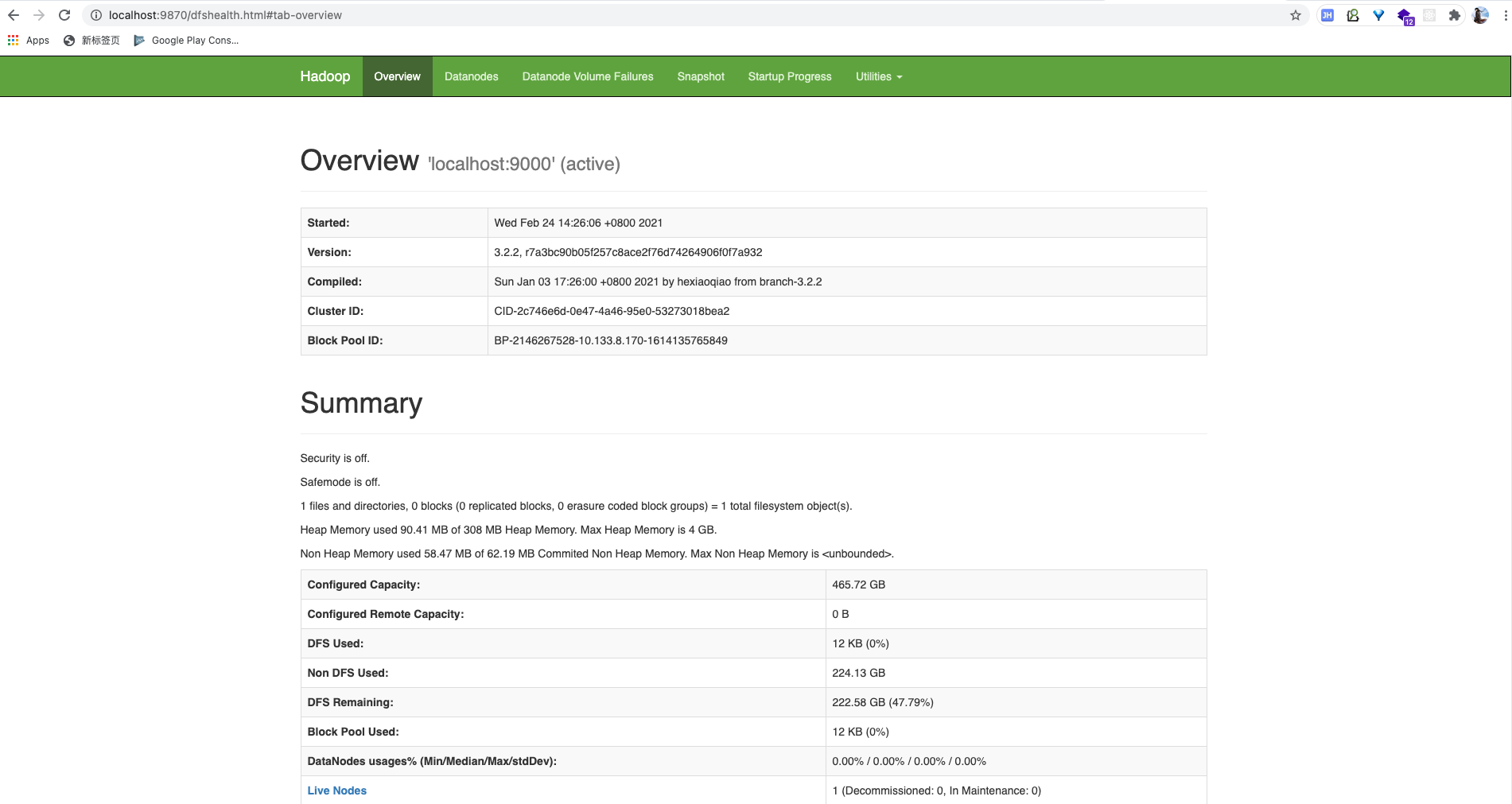
hdfs 已经启动成功
来执行一个MapReduce程序测试下
$ bin/hdfs dfs -mkdir -p /user/bane
$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml input
与单机部署一样,跑一个统计的job
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
查看结果
bin/hdfs dfs -cat output/*
结果:
1 dfsadmin
1 dfs.replication