Jaeger 链路追踪方案解析
背景
在大型的微服务架构中,一次请求下去可能会有多个rpc调用,而每个调用到的服务又会有其他的rpc调用,这个过程,会串联成一次完整的链路。一个完善的链路追踪监控,有助于我们还原每一次请求的链路,并还原其过程中的请求,返回,异常,耗时等等。。
市面上有zipkin,skyworking,Jaeger这些开源的链路追踪系统,他们各有各的优势和局限性,今天主要介绍下Jaeger
OpenTracing
在介绍jaeger之前,必须要对OpenTracing有一定的了解,OpenTracing的出现源于Google 在内部部署了一套分布式追踪系统 Dapper,并发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,现在基本上主流的分布式追踪都需要对OpenTracing进行支持
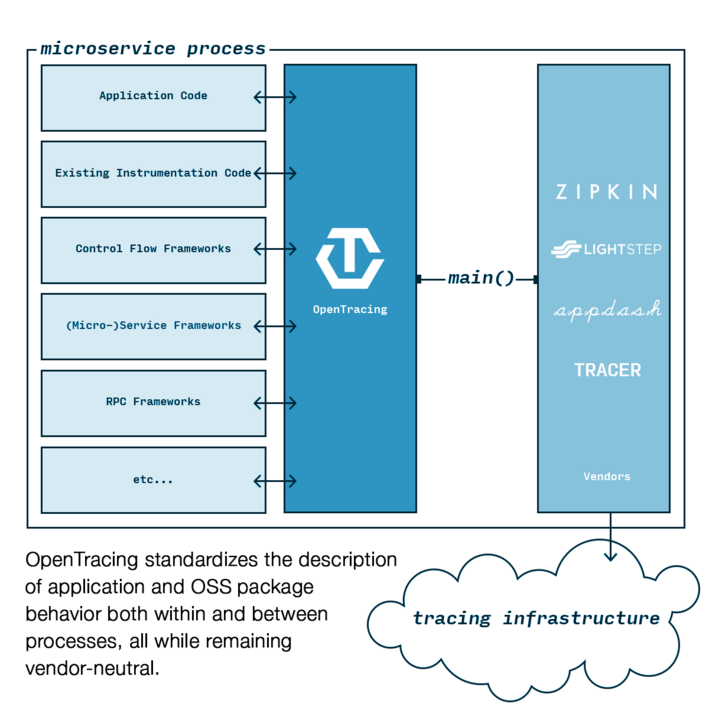
图片来源: https://www.cncf.io/blog/2016/10/20/opentracing-turning-the-lights-on-for-microservices/
- 由上图可以看到,OpenTracing更像是一个lib,他定义了数据上报的接口,无论你是何种分布式系统,你只需要对接OpenTracing,那么你就实现了分布式的追踪系统
数据模型
以下翻译自,opentracing的官方文档 https://github.com/opentracing/specification/blob/master/specification.md
Causal relationships between Spans in a single Trace
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)
Trace 是调用链,每个调用链由多个 Span 组成。Span 的单词含义是范围,可以理解为某个处理阶段。Span 和 Span 的关系称为 Reference。上图中,总共有标号为 A-H 的 8 个阶段
Temporal relationships between Spans in a single Trace
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
上图是按照时间顺序呈现的调用链。
每个阶段(Span)包含如下状态:
- 操作名称
- 起始时间
- 结束时间
- 一组 KV 值,作为阶段的标签(Span Tags)
- 阶段日志(Span Logs)
- 阶段上下文(SpanContext),其中包含 Trace ID 和 Span ID
- 引用关系(References)
阶段(Span)可以有 ChildOf 和 FollowsFrom 两种引用关系。ChildOf 用于表示父子关系,即在某个阶段中发生了另一个阶段,是最常见的阶段关系,典型的场景如调用 RPC 接口、执行 SQL、写数据。FollowsFrom 表示跟随关系,意为在某个阶段之后发生了另一个阶段,用来描述顺序执行关系。
我们对OpenTracing有了一个大概的概念,记住两个关键词Trace(调用链),Span引用范围,下面我们来看jeager
Jeager

图片来源:https://www.jaegertracing.io/docs/architecture
我们先对jeager架构的数据流转有个概念
-
jaeger-client: 实现了openTracing接口,他负责在各个服务中埋点,收集span,发送span到jaeger-agent中
-
jaeger-agent: 暂存 Jaeger Client 发来的 Span,并批量向 Jaeger Collector 发送 Span,一般每台机器上都会部署一个 Jaeger Agent。
-
jaeger-collector:接受 Jaeger Agent 发来的数据,并将其写入存储后端,目前支持采用 Cassandra 和 Elasticsearch 作为存储后端。架构图中的存储后端是 Cassandra,旁边还有一个 Spark,讲的就是可以用 Spark 等其他工具对存储后端中的 Span 进行直接分析。
-
jaeger-query & jaeger-ui:query节点,用来读取存储后端中的数据,以直观的形式呈现。 注意:query节点并不会存储数据!
运行
给一个docker-compose
version: "3"
services:
collector:
image: jaegertracing/jaeger-collector
environment:
- SPAN_STORAGE_TYPE=elasticsearch
ports:
- "14269"
- "14268:14268"
- "14267"
- "9411:9411"
restart: on-failure
command: ["/go/bin/collector-linux", "--es.server-urls=http://es-loadbalancer:9200", "--es.username=jaeger_remote_agent", "--es.password=HunterSpir!t", "--es.num-shards=1", "--span-storage.type=elasticsearch", "--log-level=error"]
agent:
image: jaegertracing/jaeger-agent
environment:
- SPAN_STORAGE_TYPE=elasticsearch
command: ["/go/bin/agent-linux", "--collector.host-port=collector:14267"]
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
restart: on-failure
depends_on:
- collector
query:
image: jaegertracing/jaeger-query
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- no_proxy=localhost
ports:
- "16686:16686"
- "16687"
restart: on-failure
command: ["/go/bin/query-linux", "--es.server-urls=http://es-loadbalancer:9200", "--span-storage.type=elasticsearch", "--log-level=debug", "--es.username=jaeger_remote_agent", "--es.password=HunterSpir!t", "--query.static-files=/go/jaeger-ui/"]
depends_on:
- agent
大概的解读下这个docker-compose
- 这是一个基于elasticsearch作为存储的编排的方式
- 分别启动3个镜像jaeger-collector,jaeger-agent,jaeger-query
启动成功后如下所示
Starting collector_1 ... done
Starting agent_1 ... done
Starting query_1 ... done
Attaching to collector_1, agent_1, query_1
agent_1 | {"level":"info","ts":1517582471.4691374,"caller":"tchannel/builder.go:89","msg":"Enabling service discovery","service":"jaeger-collector"}
agent_1 | {"level":"info","ts":1517582471.4693034,"caller":"peerlistmgr/peer_list_mgr.go:111","msg":"Registering active peer","peer":"collector:14267"}
agent_1 | {"level":"info","ts":1517582471.4709918,"caller":"agent/main.go:64","msg":"Starting agent"}
query_1 | {"level":"info","ts":1517582471.871992,"caller":"healthcheck/handler.go:99","msg":"Health Check server started","http-port":16687,"status":"unavailable"}
query_1 | {"level":"info","ts":1517582471.9079432,"caller":"query/main.go:126","msg":"Registering metrics handler with HTTP server","route":"/metrics"}
query_1 | {"level":"info","ts":1517582471.908044,"caller":"healthcheck/handler.go:133","msg":"Health Check state change","status":"ready"}
query_1 | {"level":"info","ts":1517582471.9086466,"caller":"query/main.go:135","msg":"Starting jaeger-query HTTP server","port":16686}
agent_1 | {"level":"info","ts":1517582472.472438,"caller":"peerlistmgr/peer_list_mgr.go:157","msg":"Not enough connected peers","connected":0,"required":1}
agent_1 | {"level":"info","ts":1517582472.4725628,"caller":"peerlistmgr/peer_list_mgr.go:166","msg":"Trying to connect to peer","host:port":"collector:14267"}
agent_1 | {"level":"info","ts":1517582472.4746702,"caller":"peerlistmgr/peer_list_mgr.go:176","msg":"Connected to peer","host:port":"[::]:14267"}
- 好了我们已经启动起来了将jeager
项目中注入
分两步
- 先本地和jeager建联,也就是初始化jeager-client端
- 注入代码到http的middleware中
- 注入Grpc的UnaryServerInterceptor中
贴个简易demo代码的在看一下是如何将http协议抓到jeager中的
func main() {
agentEndpointURI := "localhost:6831"
collectorEndpointURI := "http://localhost:14268/api/traces"
je, err := jaeger.NewExporter(jaeger.Options{
AgentEndpoint: agentEndpointURI,
CollectorEndpoint: collectorEndpointURI,
ServiceName: "demo",
})
if err != nil {
log.Fatalf("Failed to create the Jaeger exporter: %v", err)
}
// And now finally register it as a Trace Exporter
trace.RegisterExporter(je)
}
后话
-
上面的场景实现都比较简单,我们在实际工作中会比这要复杂的多。除了基础的数据收集外,我们还需要对中间件,存储等做到全链路的监控,而不是说只局限于每一次调用,里面还会涉及到基于opentracing去实现的特有的计算逻辑。
-
无论是jeager还是zipkin他其实都是侵入式的,都需要在代码中注入类似于拦截器的代码。 Istio 推出了非侵入式的trace,Distributed Tracing,他提供一种网关式的实现,完全独立于项目的中间件,本质是说,让中间件更轻量其实是,这是符合service Mesh的理念的一种实现。