起因是接了一个在线知识学习平台的小外包,用的 Rails 的 Grape 做的 API,刚开始的时候没多少个人,所以就丢在了一个2C8G的服务器上面,跑的很稳健,基本上有小的 Bug,出于职业素养的原因也就顺手修了。当时偷懒排行榜写的比较慢,代码大概是这样子:
UserActivityLog.where(category: 'study').group(:user_id).sum(:duration)
其实最开始时候,数据是跑在 mysql 容器里面的,后来发现太慢了,而且本地 mysql 读写很占 CPU 内存,我就都搬上了 RDS,于是第一次优化就是这样,当时速度,稳定性已经很可观了。
大概在2020年9月1日的时候,发现接口有点慢,我去 RDS 上面看了下,大部分就是上面语句引起的慢查询,所以我就加了一个 index
add_index(:user_activity_logs, [:category, :user_id, :duration])
于是慢查询没有了,虽然这个接口的返回还是很感人,但是当时的确降低了一半的 CPU 使用量。所以我也就断开了链接继续干别的事情。但是到了9月3号的时候,我在微信运营平台收到了很多反馈说登录不上,非常慢。我打开一看的确是非常非常慢,3个请求基本上有2次会断开。这个时候我打开了第二个服务器(2C8G),也 deploy 了一个后端服务,发现 CPU 下降了一半,当时 NGINX EST的连接数大概在500左右。按照惯例,我又继续断开了链接,继续玩别的去了。
期间改了一次 NGINX 的配置,开了 epoll,用了 worker_processes 2;
到了4号的时候,也就是昨天,小程序PV已经有20多万,NGINX EST 大概在 3000,CPU 基本在 95%,卡出翔,我知道了这俩服务器不行了,那条查询太慢了,光加 index 已经不管用了。
所以,经过这么多次的优化,我感觉配置上能优化的已经不多了。于是我就想了一个新的解决方案:
- 加了1个 2C4G,1个4C8G 的服务器,买了一个月,花了500块;
- 打开代码编辑器,新写一张统计表;
- 负载均衡到4个机器上面;其中一个就是开1个意思一下;
upstream {
server xxx.xxx.xxx.1 weight=1;
server xxx.xxx.xxx.2 weight=3;
server xxx.xxx.xxx.3 weight=4;
server xxx.xxx.xxx.4 weight=8;
}
现在大概 Nginx 大概是这么个分发逻辑,按照谁比较强,谁比较空来分发。每台机器上面对应了1,3,4,8个 docker 容器。所以现在大家都很稳定。
大概是这么一个架构
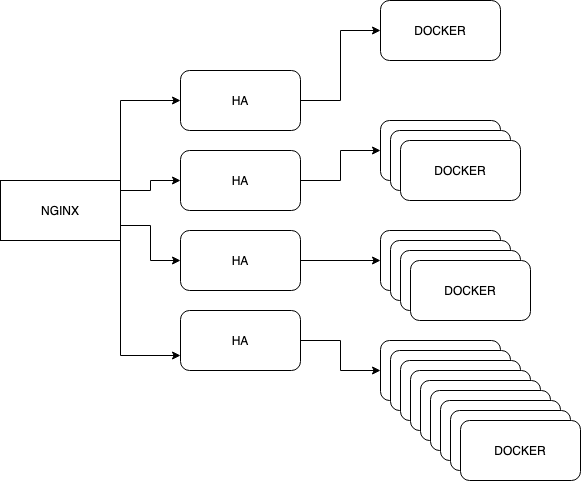
之所以前面有个 HAProxy,是因为我写在了 docker-compose.yml 里面,这样 link 了之后可以自动发现,但是对外只有一个出口,这是一个偷懒的方式。