1.背景
elasticsearch 5.0 版本开始引入了预处理节点[Ingest Node]。
2. 什么是预处理
在实际索引发生之前,可以使用Ingest Node对文档进行预处理。此预处理由接收节点进行,该节点拦截批量和索引请求,应用转换,然后将文档传递回索引或批量api。
简单的理解,就是类似我们使用的拦截器。在数据实际落库之前,对数据进行处理。
3. 预处理的使用场景
我们都知道,很多时候,我们用elk进行日志收集。但是,我们的日志很多时候就是一个包含了很多数据的字符串,那么,我们在把日志收集到elasticsearch的时候,我们希望对数据进行解析,把一些信息提取出来,这样,我们可以,更方便的检索日志。
4.预处理的用法
4.1 开启节点的预处理功能,默认是开启的。
如果需要关闭,在elasticsearh.yaml中
node.ingest: false
4.2 我们需要定义一个流水线,来实现我们要做的操作。一个pipeline中可以有多个processors。
例如,我们要创建一个预处理器,来给字段赋值。把 foo 字段的值设置为 "new"
PUT _ingest/pipeline/my_pipeline_id
{
"description" : "describe pipeline",
"processors" : [
{
"set" : {
"field": "foo",
"value": "new"
}
}
]
}
PUT my-index/_doc/my-id?pipeline=my_pipeline_id
{ "foo": "bar" }
结果:
{
"_index": "my-index",
"_type": "_doc",
"_id": "my-id",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
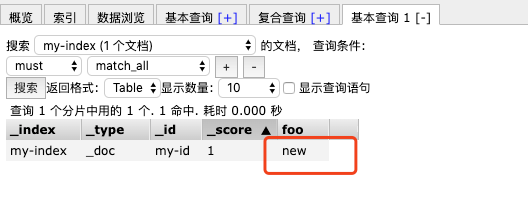
查看数据,值的确被设置为了new
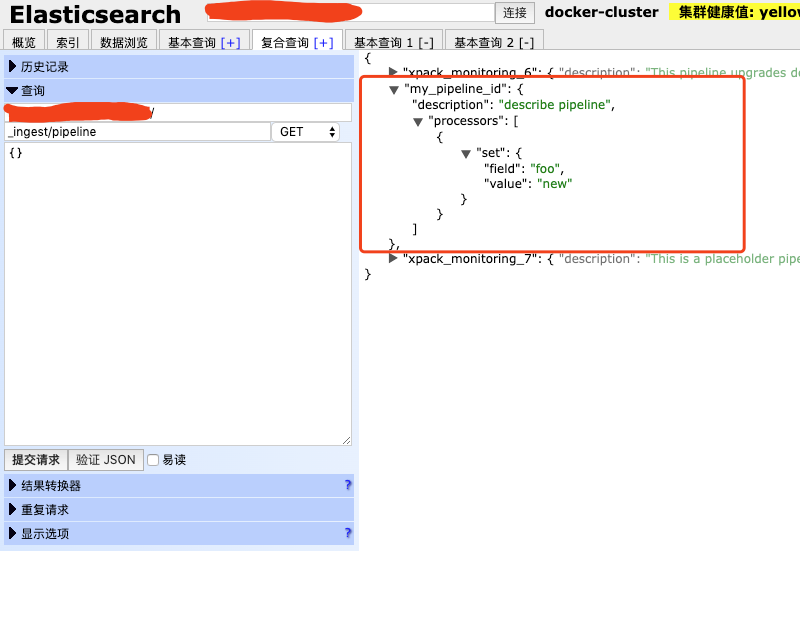
4.3 查看预处理列表
GET _ingest/pipeline
可以看到刚才创建的预处理器
4.4 删除预处理器
DELETE _ingest/pipeline/my_pipeline_id
elasticsearch 还提供了很多种处理器,可以去官网看下
https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest-processors.html
参考资料:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/ingest.html