随着微服务的发展,目前的应用很多都是分布式的,服务会落在不同的节点上。这个时候,日志的查看就是一个问题了。之前单应用的时候,我们只要去服务器上看下日志文件就行。分布式的应用,首先要确定是哪个服务出的问题,该服务在哪个节点上。
那么,解决这个问题的方向,当然就是日志的收集。目前行业主要有elk,splunk等方案。
我们今天说下elk,elk指的是elasticsearch,logstash,kibana.
- elasticsearch : 搜索引擎
- filebeat:日志收集
- logstash:日志解析过滤
- kibana:展示面板
考虑到logstash的性能消耗比较大,而且,elasticsearch对json的支持,决定不使用logstash ,直接打出json格式的日志,然后,通过filebeat直接发送到elasticsearch。这里我们用docker来部署elasticsearch和kibana。当前的版本是7.2.4。
通过dockerhub上对镜像的介绍,kibana默认访问的是localhost:9200。但是,我们是通过docker部署的,elasticsearch和kibana在两个容器中,查看官方文档 https://www.elastic.co/guide/en/kibana/current/docker.html 可以通过环境变量 ELASTICSEARCH_HOSTS 指点elasticsearch的地址。
或者配置docker网络走网桥模式,两个容器用同一个network,也可以互通
编写docker-compose文件
version: '3'
services:
kibina-elasticsearch:
image: elasticsearch:7.4.2
container_name: kibina-elasticsearch
restart: always
ports:
- "9200:9200"
- "9300:9300"
environment:
- "discovery.type=single-node"
kibina:
image: kibana:7.4.2
container_name: kibina-ui
restart: always
ports:
- "5601:5601"
environment:
- "ELASTICSEARCH_HOSTS=http://192.168.122.115:9200"
到此,服务端已经搭建完成,下面,我们需要部署客户端的filebeat。
下载对应版本的filebeat,然后修改 filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/logs/ithere/*
output.elasticsearch:
hosts: ["192.168.122.115:9200"]
启动filebeat
./filebeat -e -c filebeat.yml
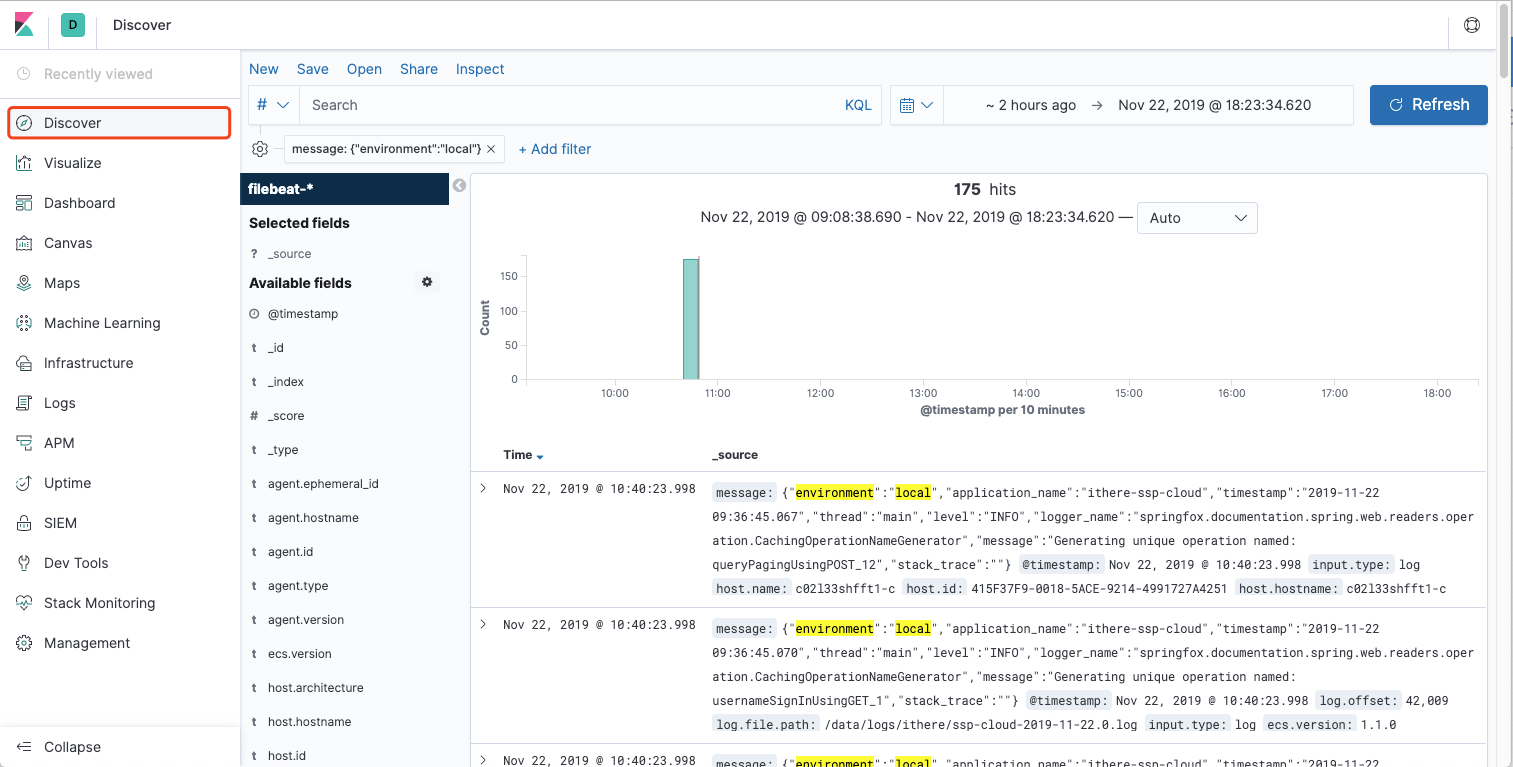
下面去kibana看下效果
默认情况下,kibana没有配置索引
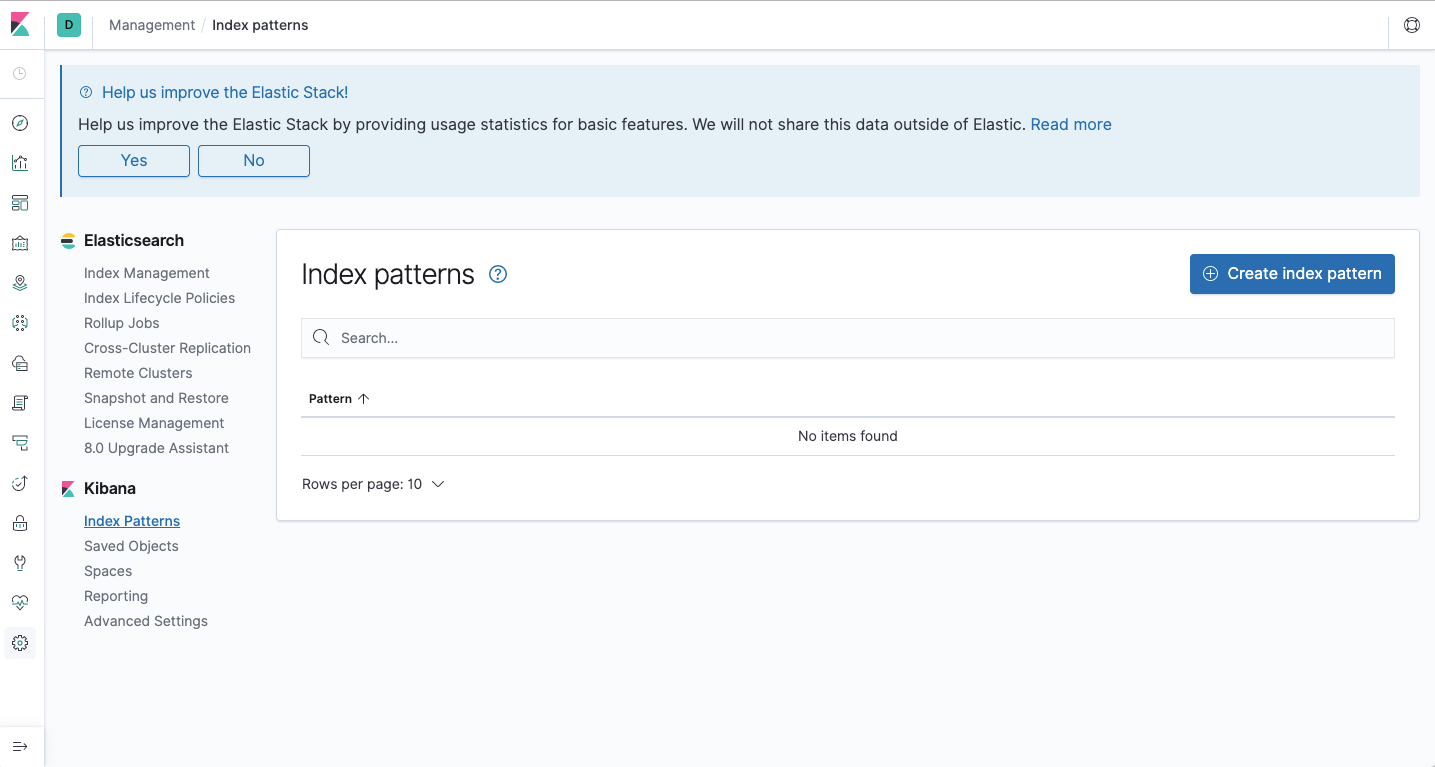
我们去创建一个索引的正则,可以看到当前已经有一个索引了
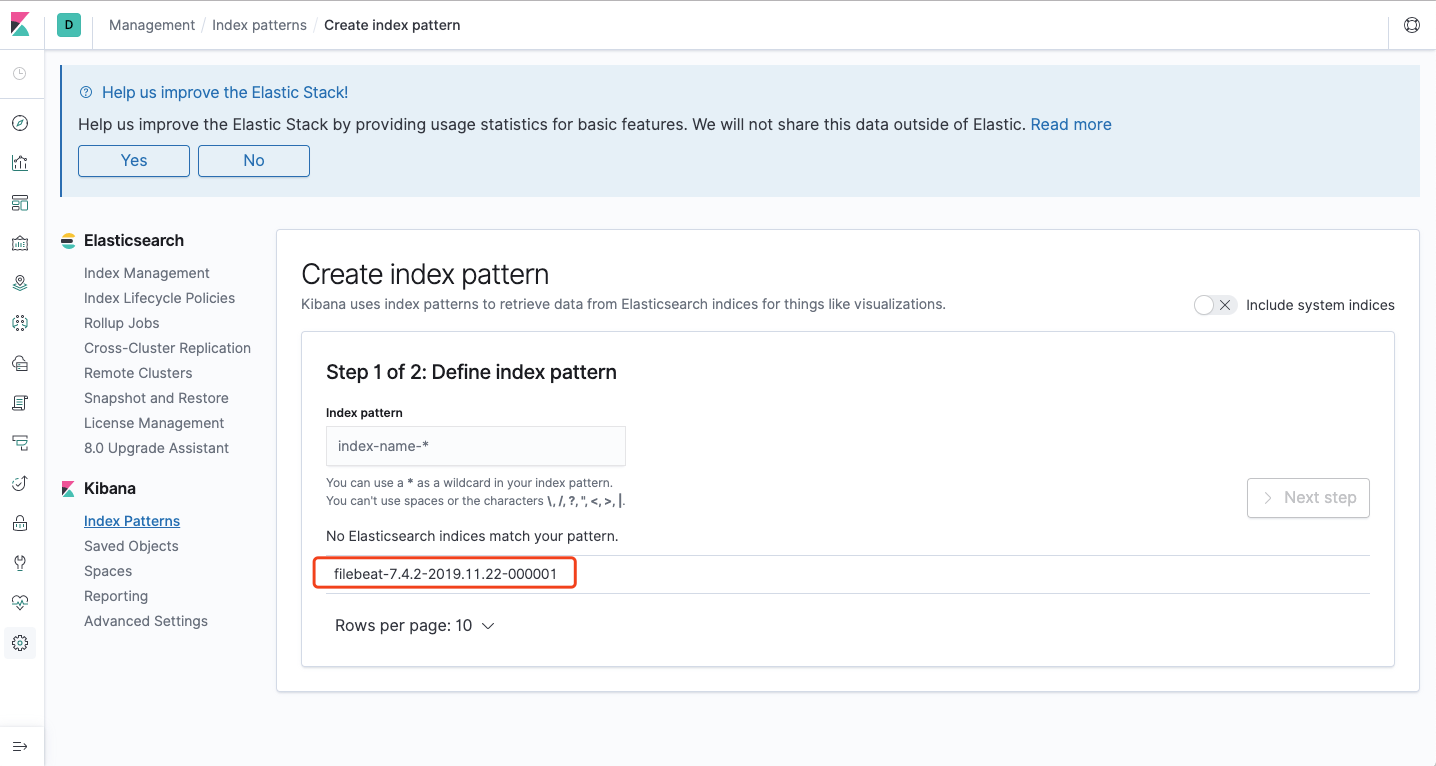
所以我们创建一个filebeat开头的索引规则
在discover中就可以看到结果了