方案一:LM Studio部署
打开下面链接下载LM Studio,支持Windows、Mac和Linux
👾 LM Studio - Discover and run local LLMs
点击发现按钮,搜索Deepseek
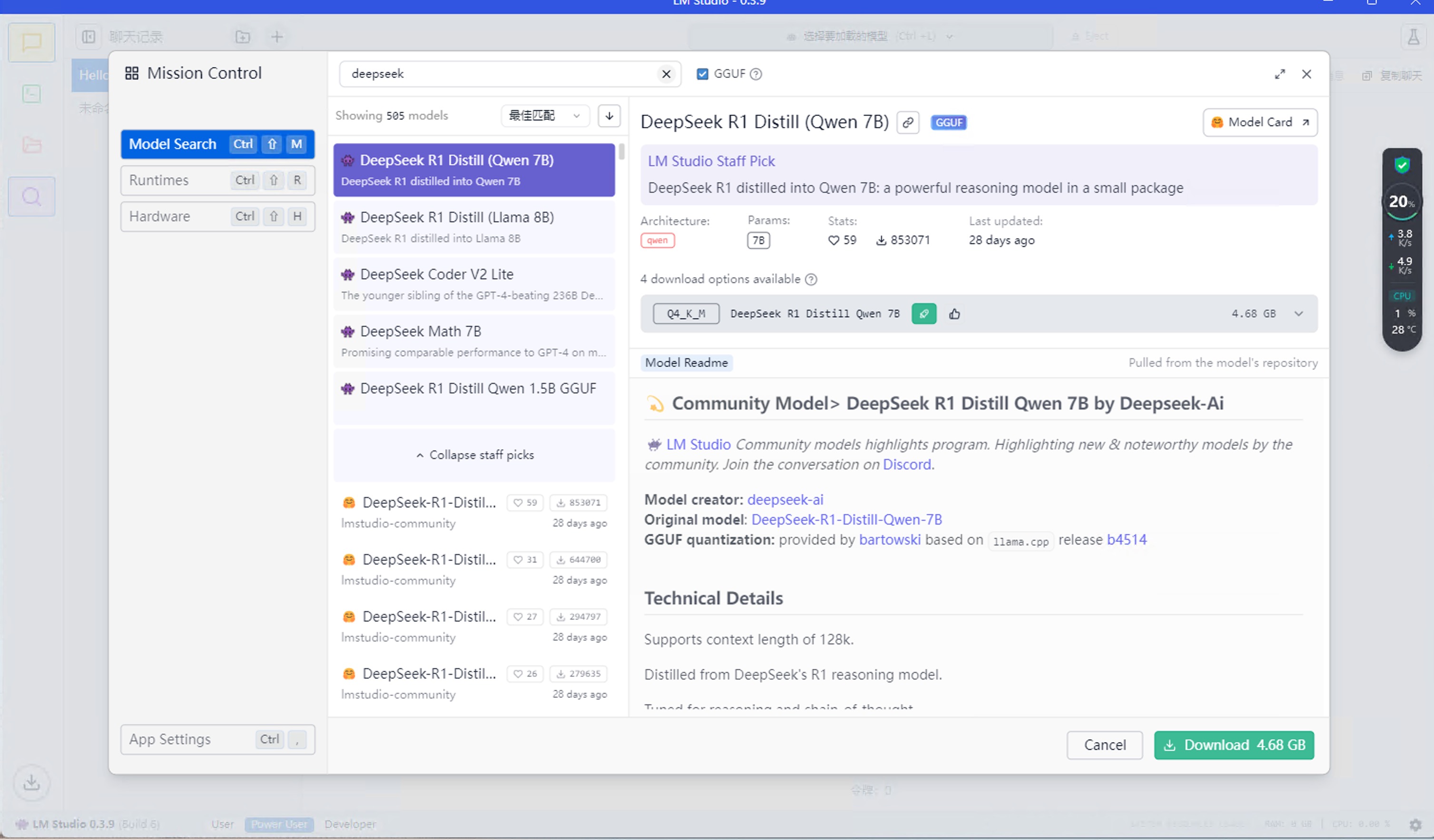
会看到很多搜索结果和模型详情,选择适合本地算力的模型,点击Download,关闭弹窗,回到聊天界面
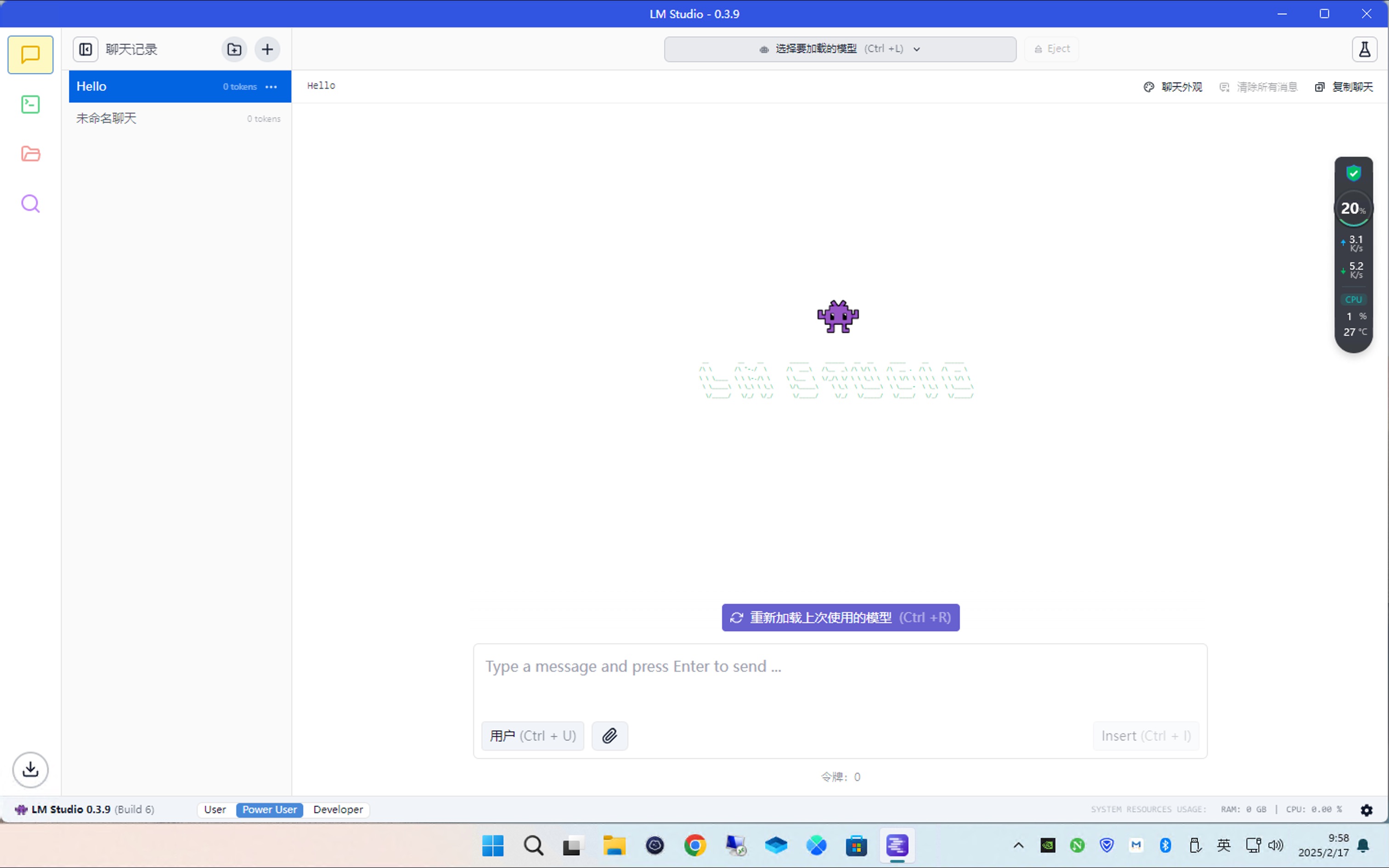
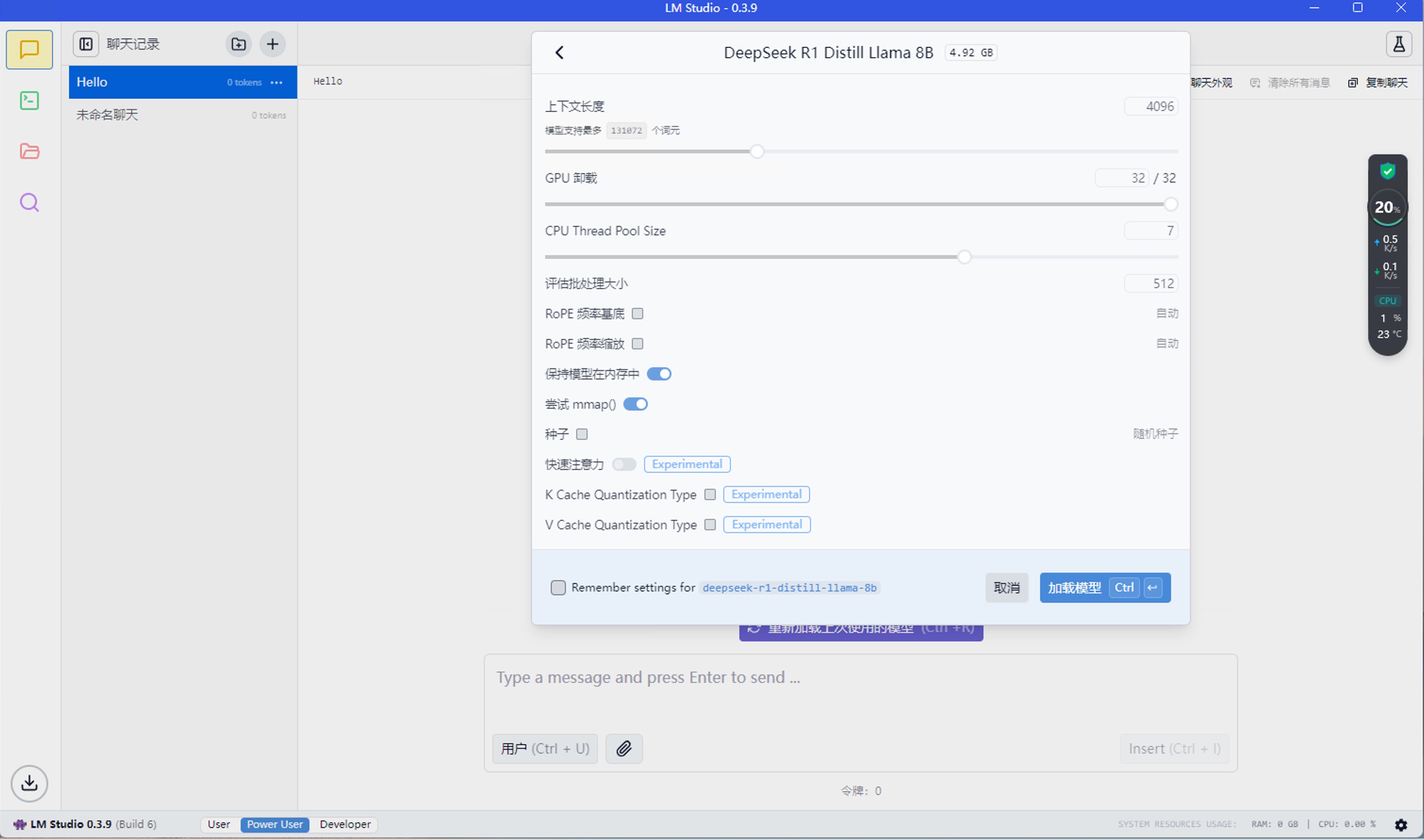
在上方选择要加载的模型,选中后使用默认参数,点击加载
然后就可以愉快的跟本地DeepSeek聊天了
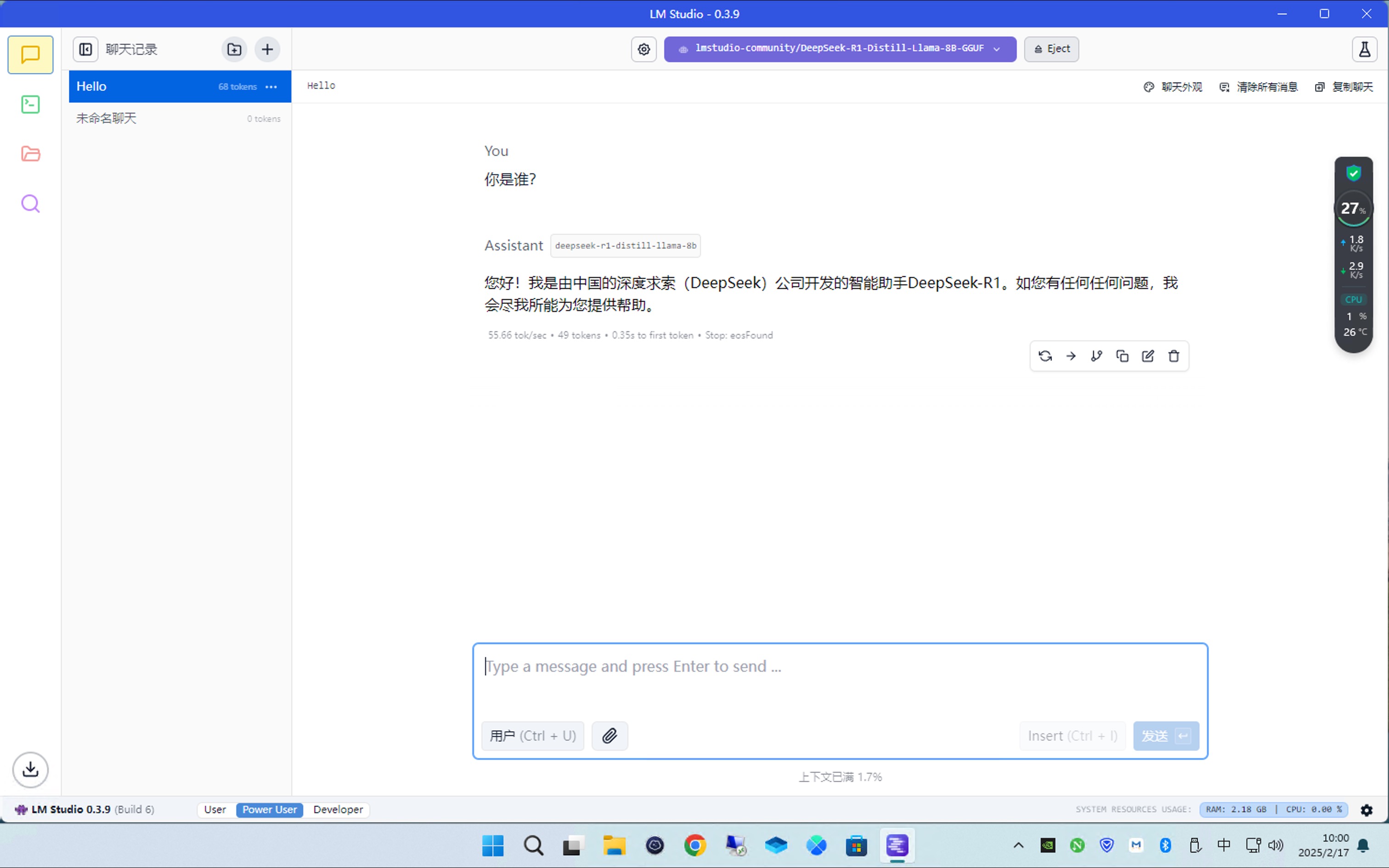
可以看到输出速度和总共输出的token数量
LM Studio提供openai格式的api接口,点击聊天按钮下面的term图标
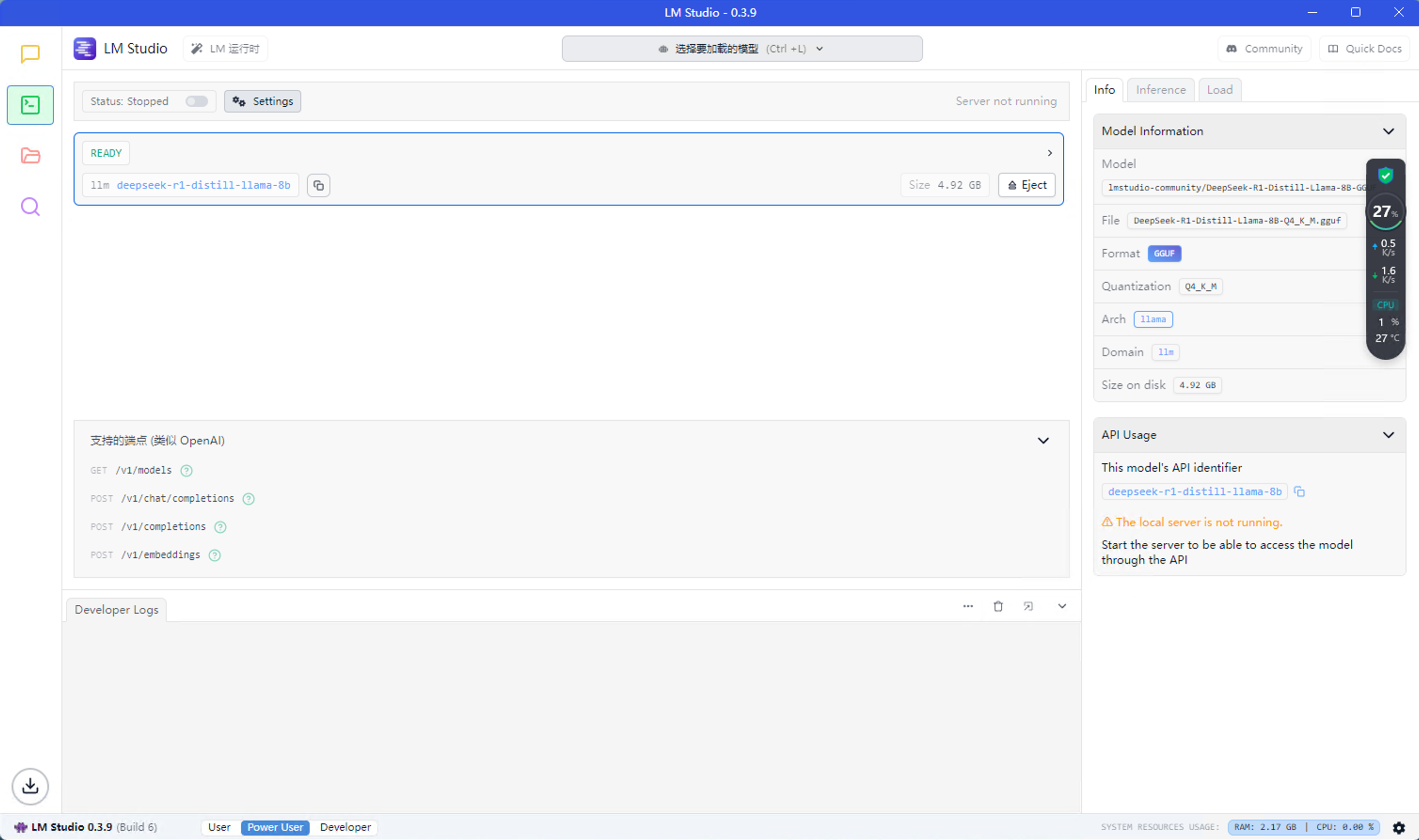
可以看到支持的API路由等等信息
方案二:Ollama部署
打开下面的链接下载Ollama
安装ollama
安装完毕后打开cmd窗口
输入以下命令直接启动模型
ollama run deepseek-r1:1.5b --verbbos
执行完命令ollama会自动去下载模型文件,可以在ollama数据库看到支持的模型
运行起来可以直接在命令行聊天
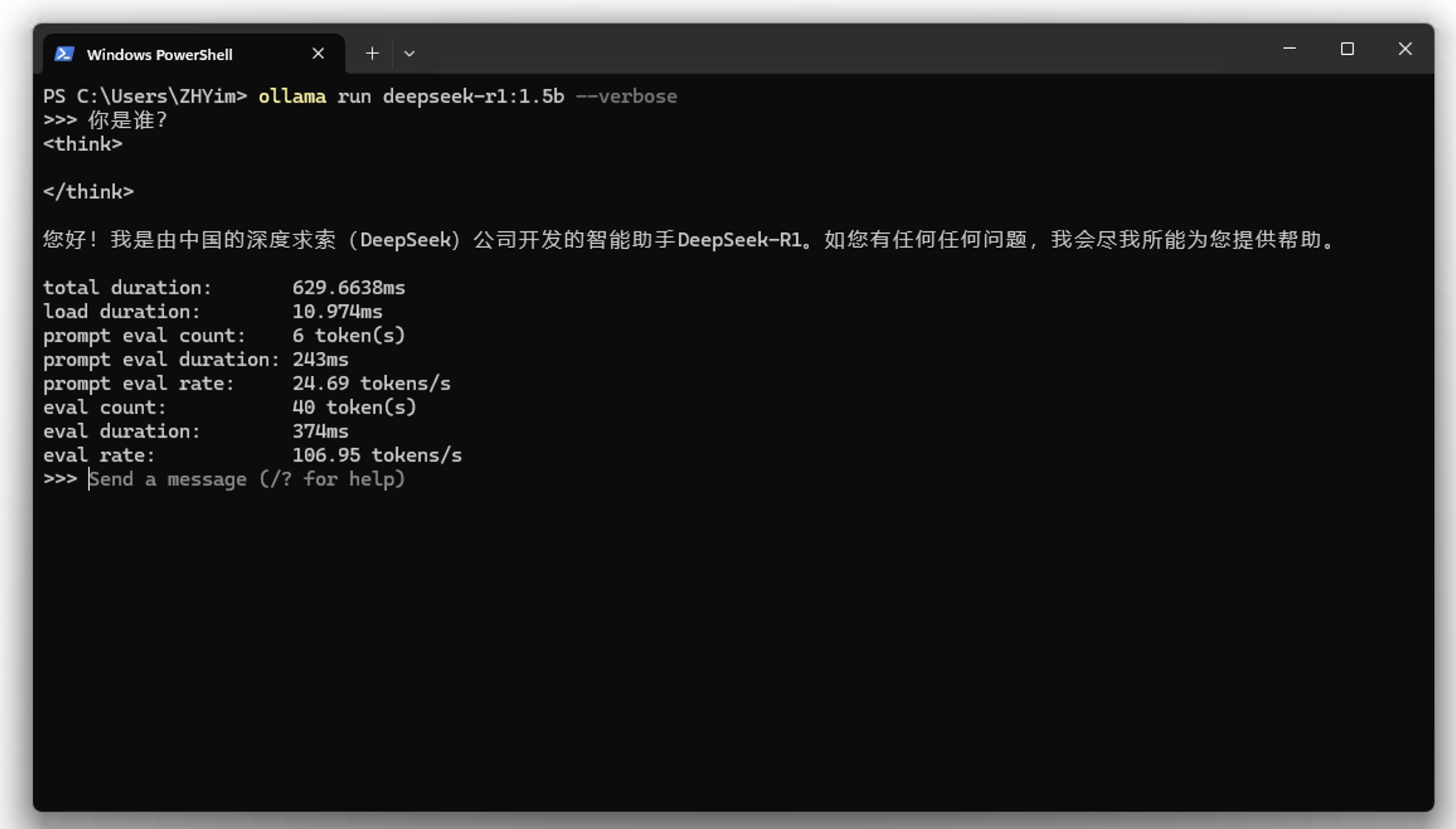
可以看到输出的平均速度和一些基本信息
在Chrome浏览器插件PageAssist中使用
安装PageAssist插件,点击插件图标,会自动搜索本地的ollama服务

在选择模型的下拉框可以看到本地ollama启动的模型,选择后就可以愉快的聊天了
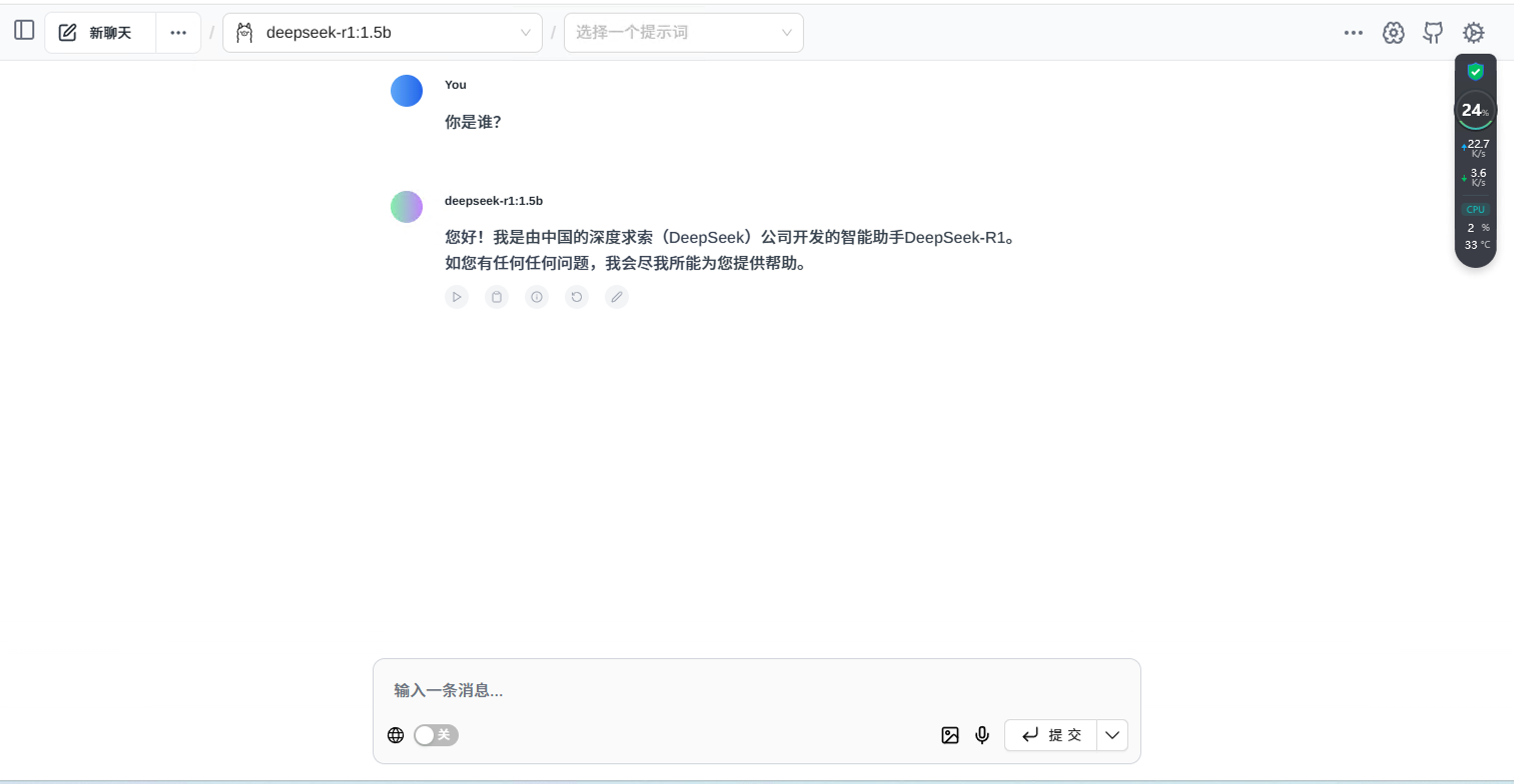
ollama也提供openai格式的api接口,地址是http://127.0.0.1:11434/v1
方案三:GPUStack部署
gpustack是一个Github开源项目
核心特性
-
广泛的硬件兼容性:支持管理 Apple Mac、Windows PC 和 Linux 服务器上不同品牌的 GPU。
-
广泛的模型支持:从大语言模型 LLM、多模态模型 VLM 到 Diffusion 扩散模型、STT 与 TTS 语音模型、文本嵌入和重排序模型的广泛支持。
-
异构 GPU 支持与扩展:轻松添加异构 GPU 资源,按需扩展算力规模。
-
分布式推理:支持单机多卡并行和多机多卡并行推理。
-
多推理后端支持:支持 llama-box(基于 llama.cpp 和 stable-diffusion.cpp)、vox-box 和 vLLM 作为推理后端。
-
轻量级 Python 包:最小的依赖和操作开销。
-
OpenAI 兼容 API:提供兼容 OpenAI 标准的 API 服务。
-
用户和 API 密钥管理:简化用户和 API 密钥的管理流程。
-
GPU 指标监控:实时监控 GPU 性能和利用率。
-
Token 使用和速率统计:有效跟踪 token 使用情况,并管理速率限制。
适合企业级的部署,项目地址是
GitHub - gpustack/gpustack: Manage GPU clusters for running AI models
在服务器上使用docker-compose部署
version: "3.8"
services:
gpustack:
container_name: gpustack
image: gpustack/gpustack:main
shm_size: 512g
volumes:
- ./volumes/gpustack:/var/lib/gpustack
- /home/user/models:/models
ports:
- 3000:80
environment:
TZ: Asia/Shanghai
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["all"]
capabilities: [gpu]
restart: always
networks:
default:
name: llm
ipam:
driver: default
config:
- subnet: 10.168.0.0/16
docker compose up -d
容器启动后在浏览器打开http://127.0.0.1:3000
默认用户名是admin
默认密码使用以下命令获取
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
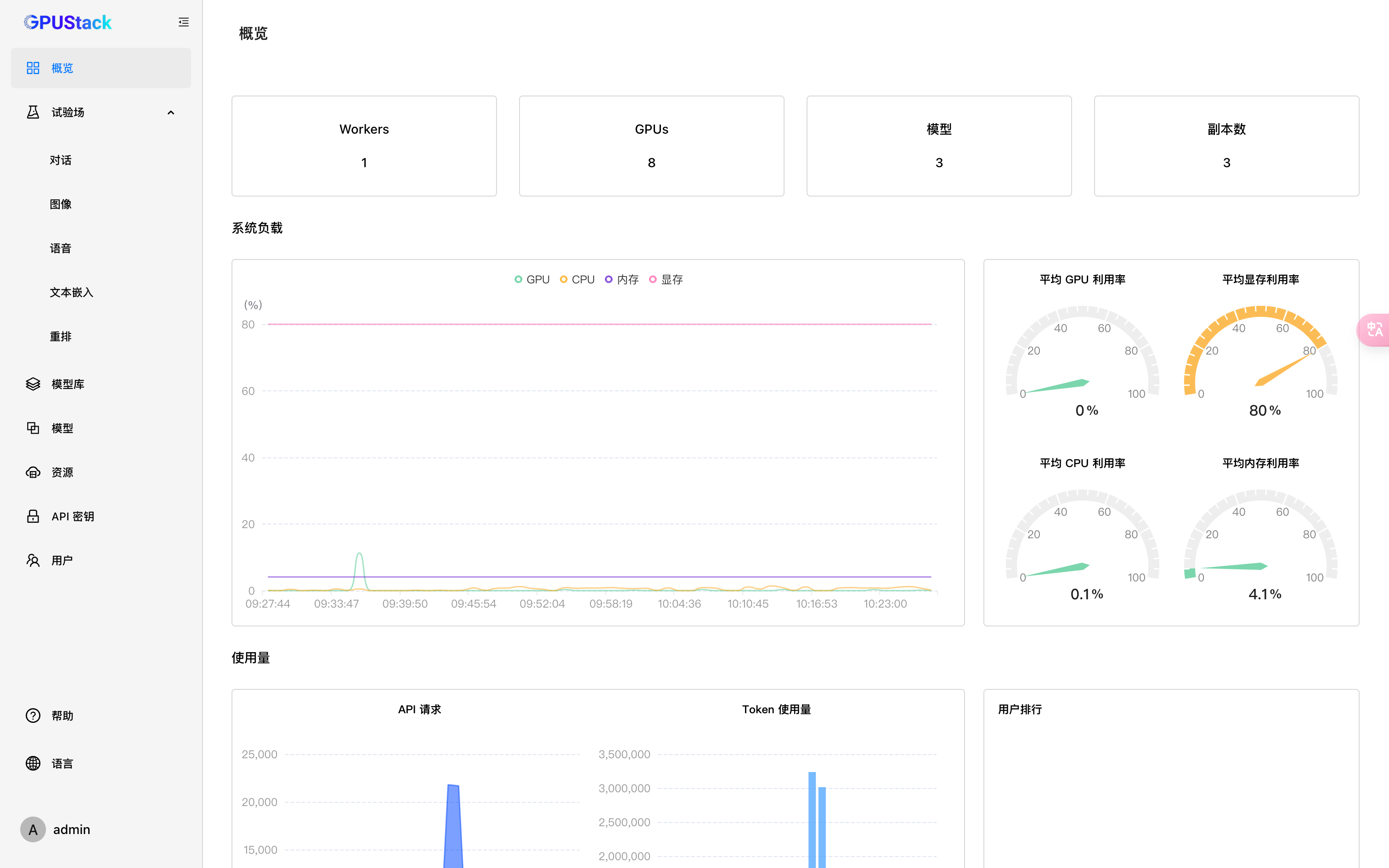
首页展示系统信息和使用量相关的信息
点击模型库,搜索deepseek
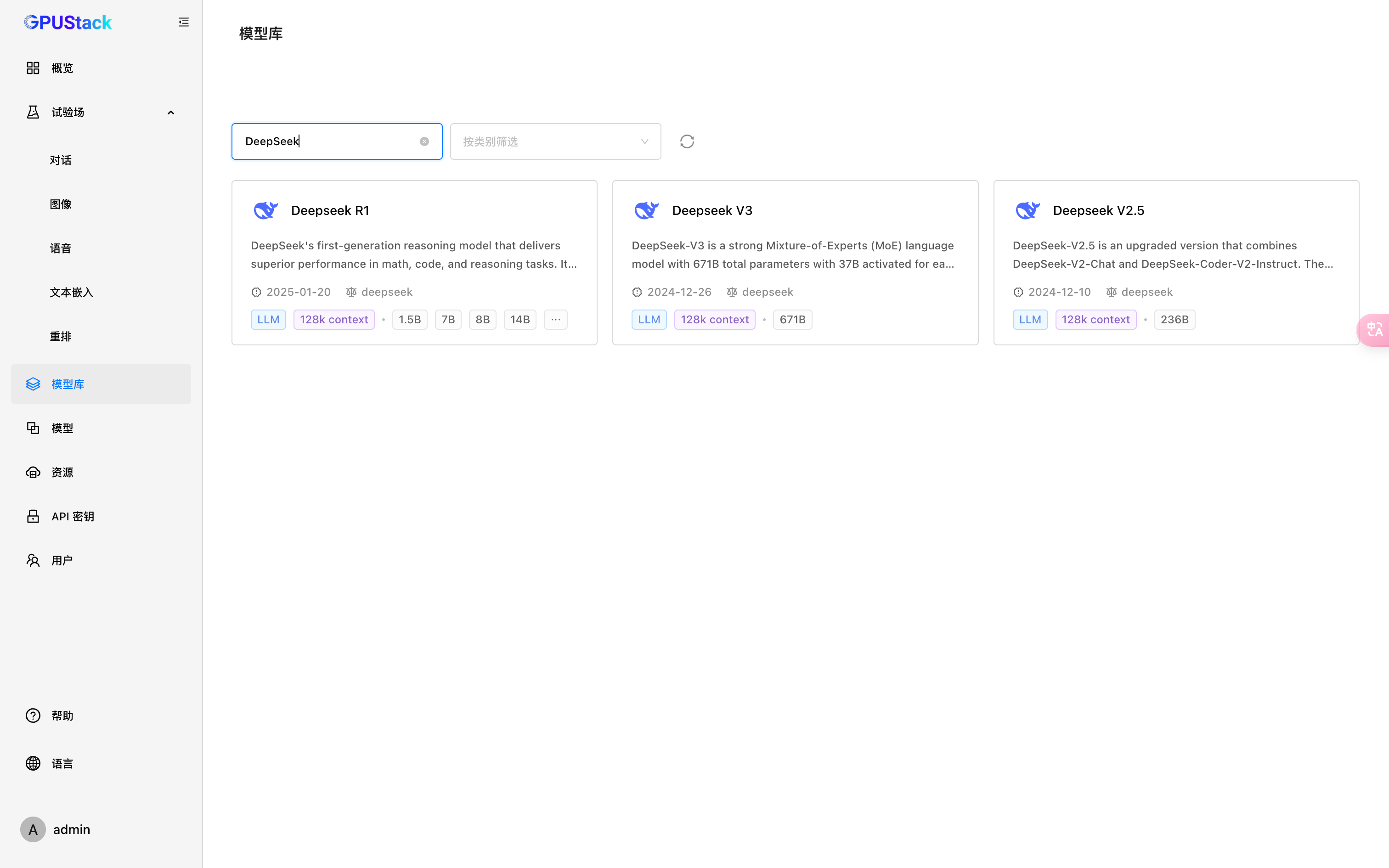
点击DeepSeek R1
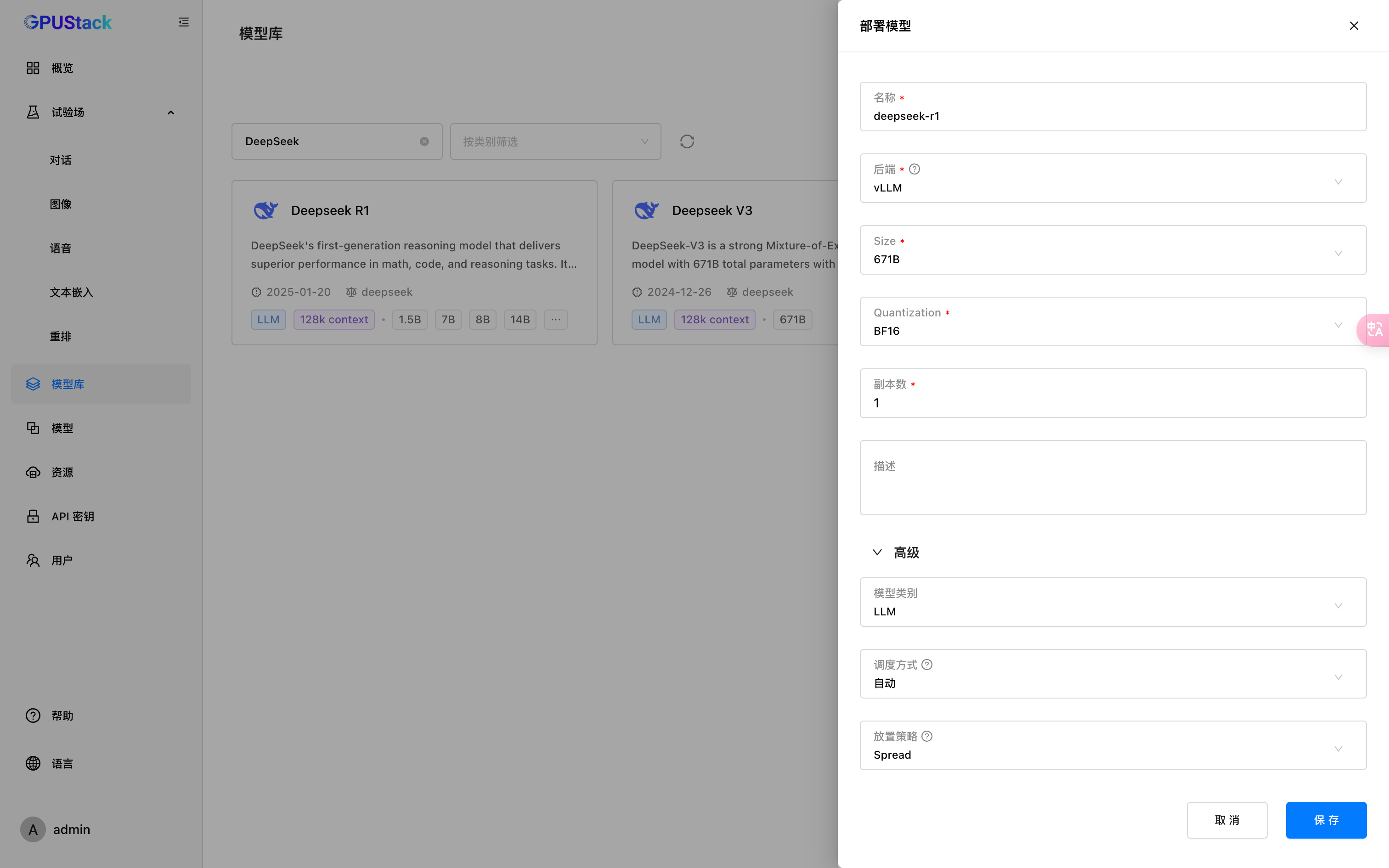
如果是量化版,使用vllama-box推理,如果是全量版本,使用vllm推理
点击保存,再点击菜单栏的模型
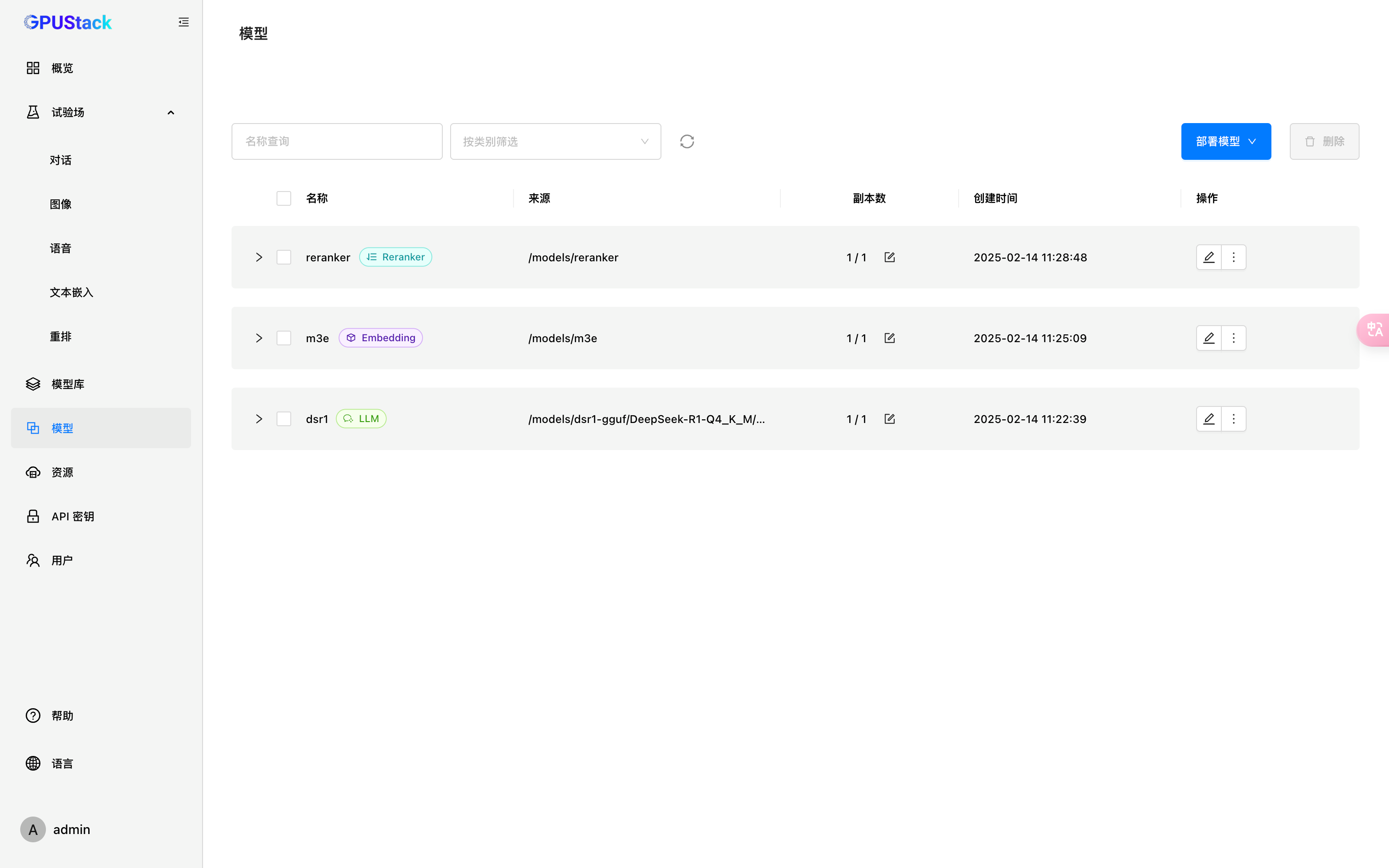
这里会列出部署的模型、类型等信息
点击试验场进行聊天
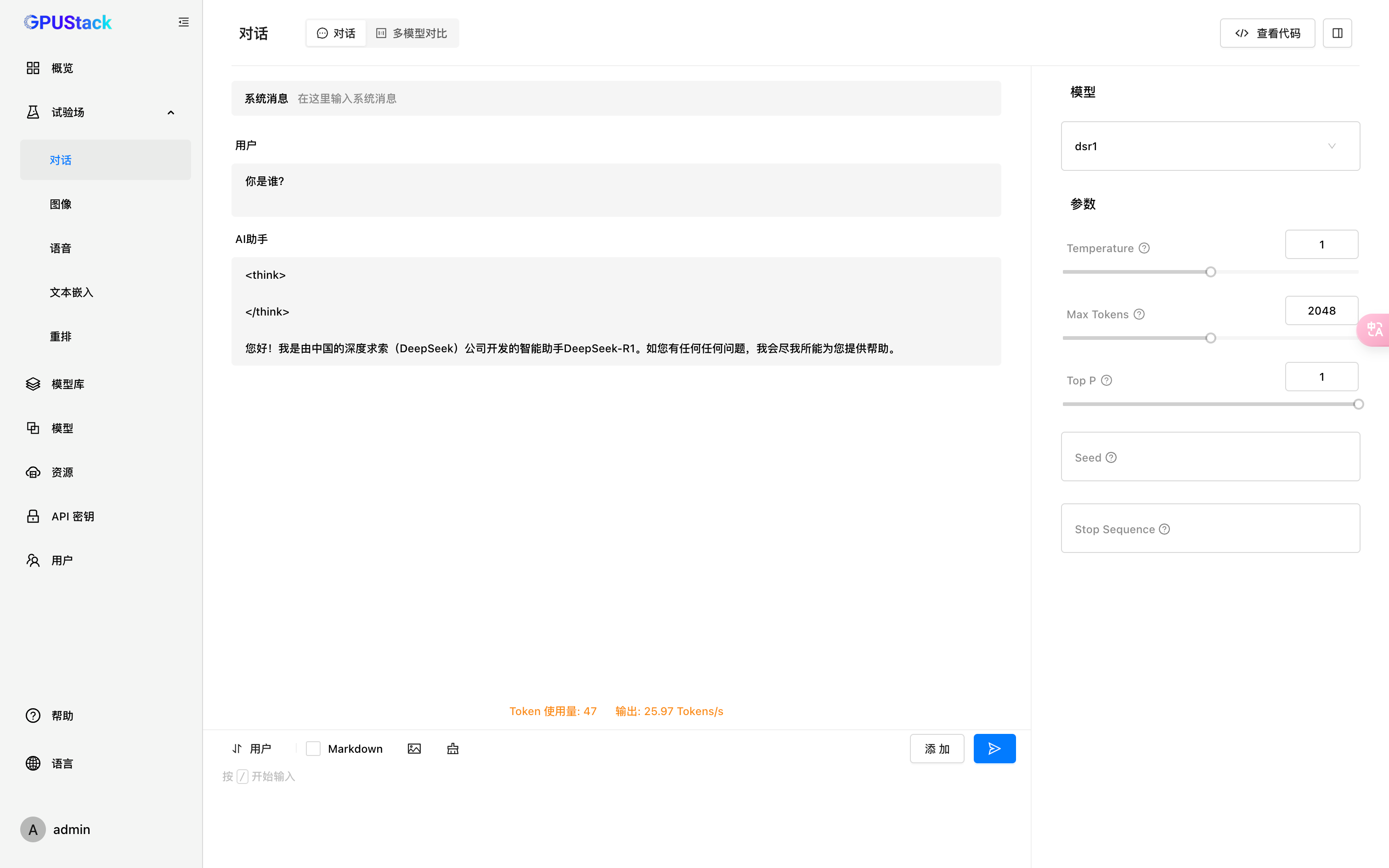
会展示模型使用量和输出速度
GPUstack也支持openai格式的api,方便集成到支持openai的聊天框架,这里展示集成到Page Assist插件
先点击API密钥,创建一个API密钥
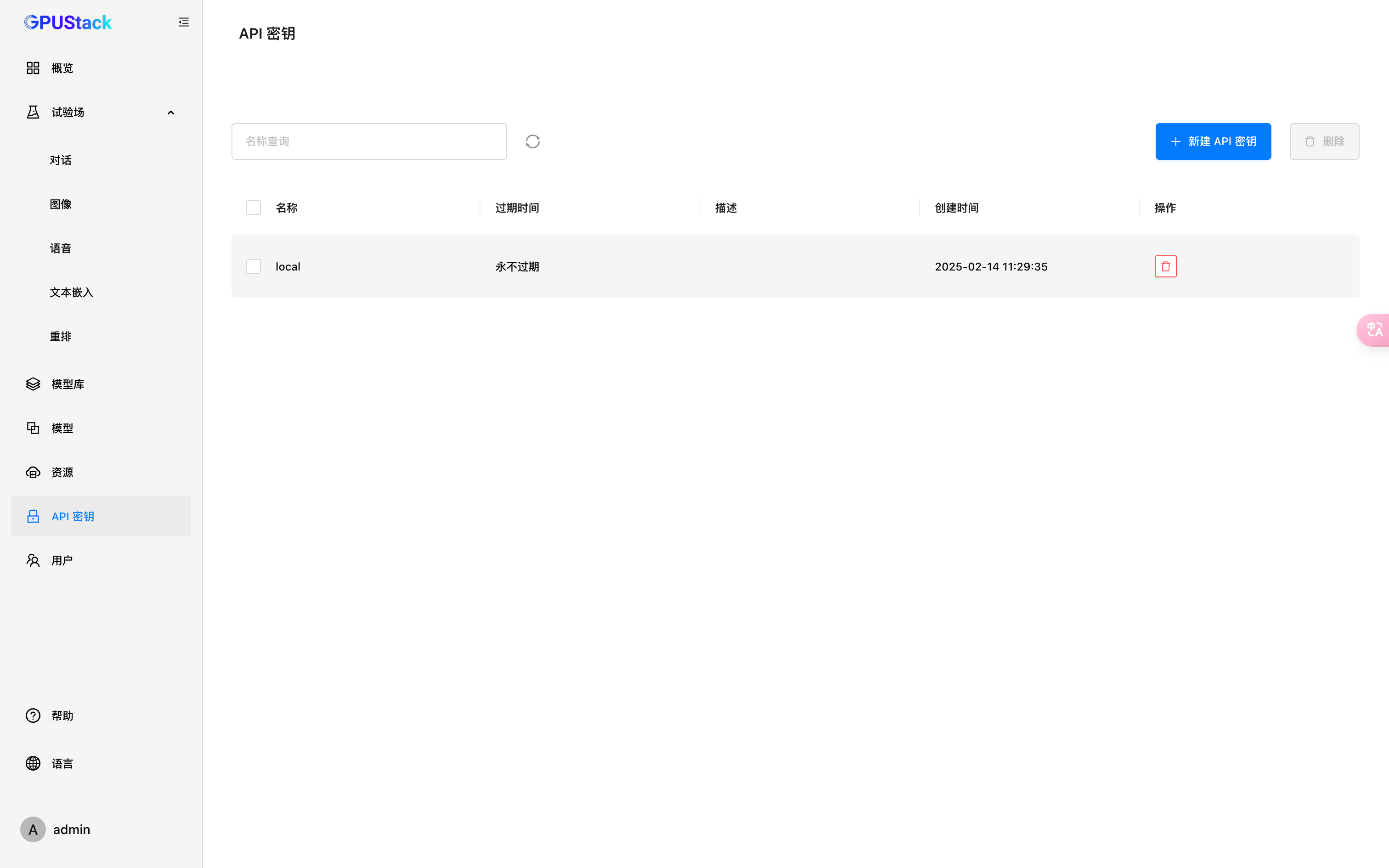
密钥妥善保管,只在创建时展示一次
在PageAssist中,点击右上角的设置-OpenAI兼容API-输出GPUStack的地址和刚刚创建的api key
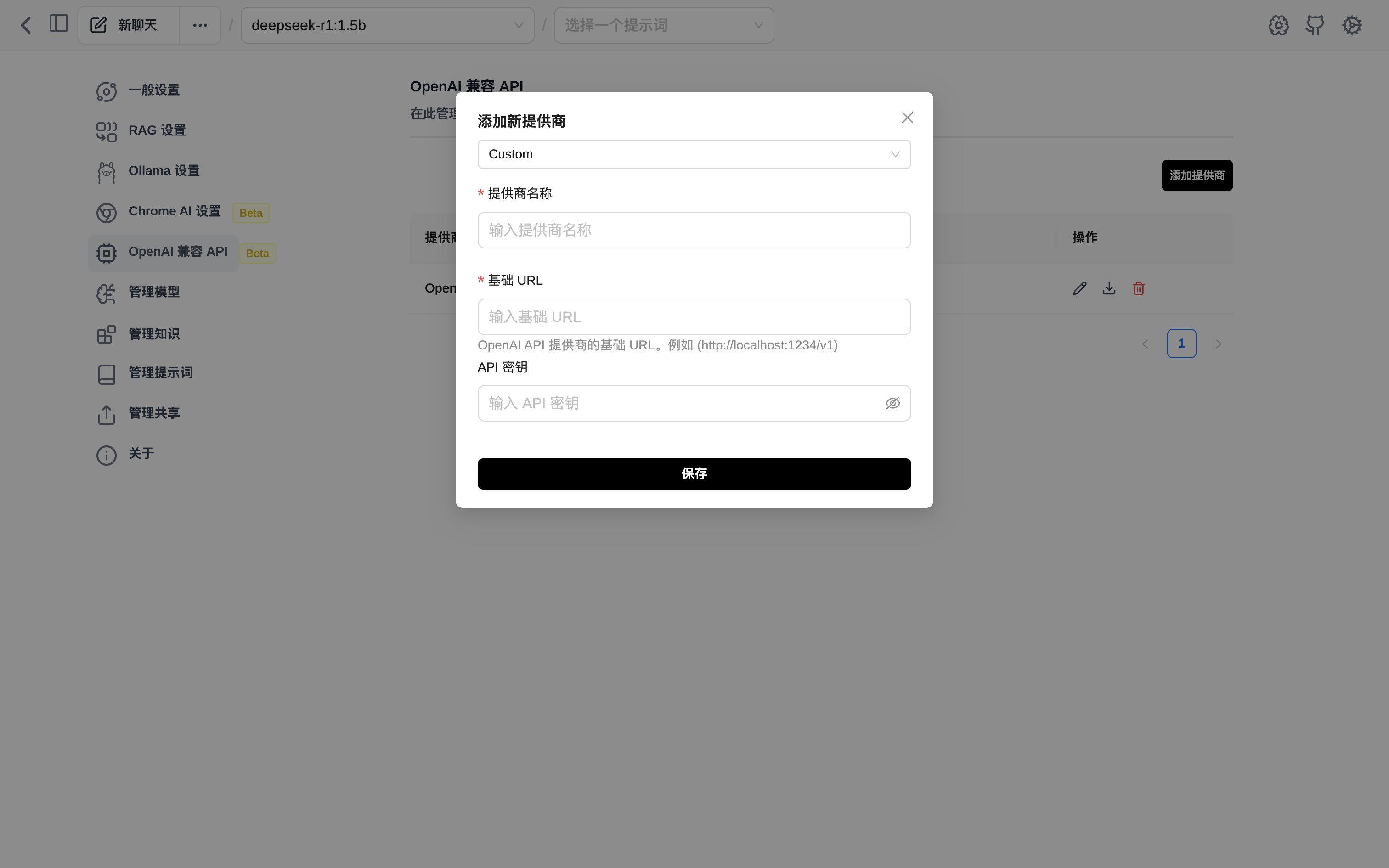
点击保存,在模型管理中选中刚才部署的模型

支持聊天模型和潜入模型,潜入模型用于知识库
点击左上角的新聊天,然后选择刚才添加的模型
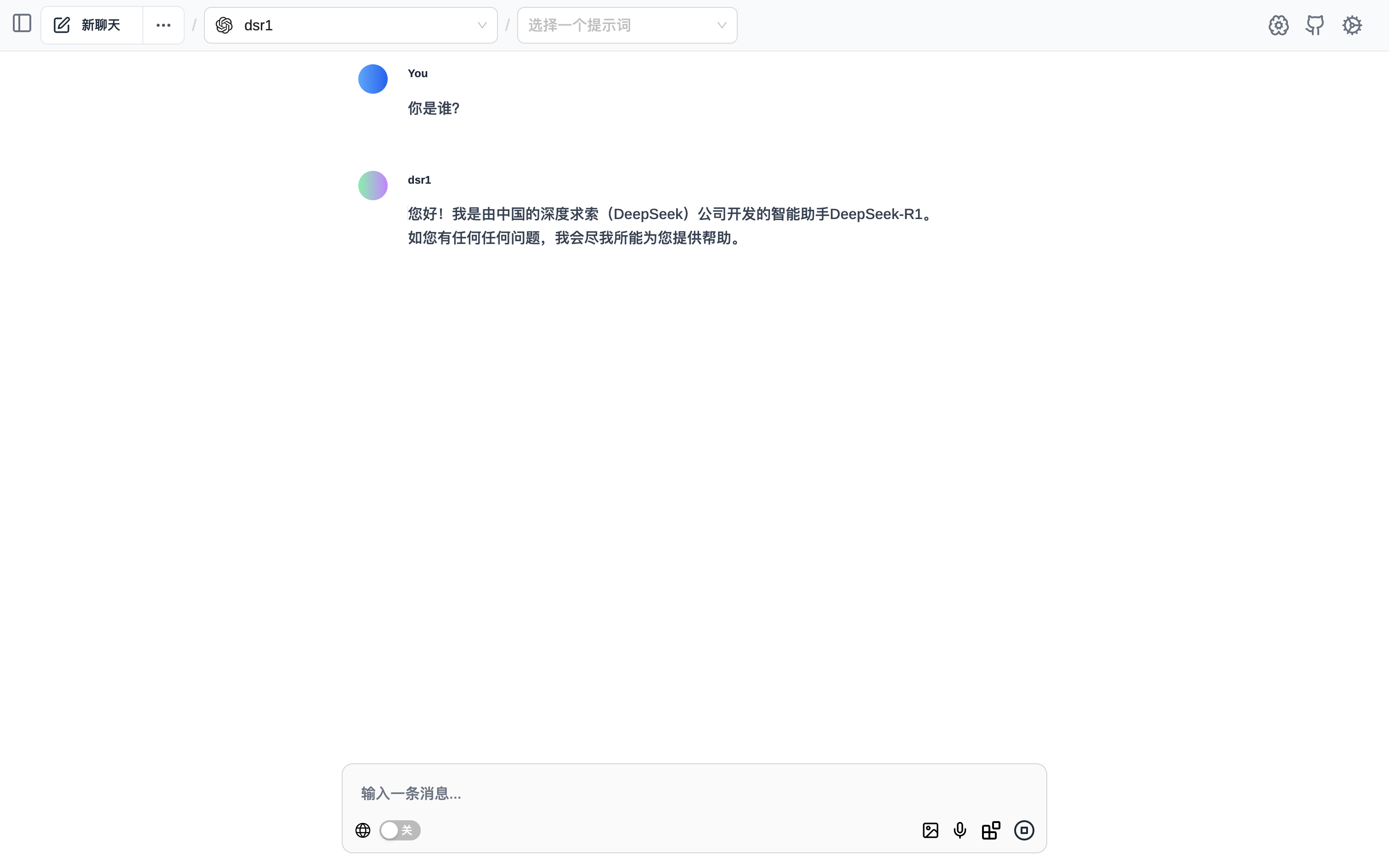
就可以愉快的聊天了
以上就是在本地部署DeepSeek-R1的三种方案