前言
搜索就是搜寻,查找,百度 在IT行业中就是指输入关键字,通过相应的算法,查询并返 回所需要的信息。比较日常的话可能就是对数据库的查询搜索 SELECT .. WHERE ..之类的云云。但是比如说像百度一样的根据文本框的文字来进行拆分查找,并且数据量可以达到500W以上的话 数据库能承受得住吗,要多久呢!
1.没有通过高效的索引方式,所以查询的速度在大量数据的情况下是很慢。
2.搜索效果比较差,只能对用户输入的完整关键字首尾位进行模糊匹配。用户搜索的结果误多输入一个字符,可能就导致查询出的结果远离用户的预期 这时候就需要我们的主角来帮助我们来实现这个需求。
Lucene

Lucene、Solr、Elasticsearch关系
Lucene:底层的API,工具包
Solr:基于Lucene开发的企业级的搜索引擎产品
Elasticsearch:基于Lucene开发的企业级的搜索引擎产品
Lucene的基本使用
创建索引的流程(别说了盗图的)
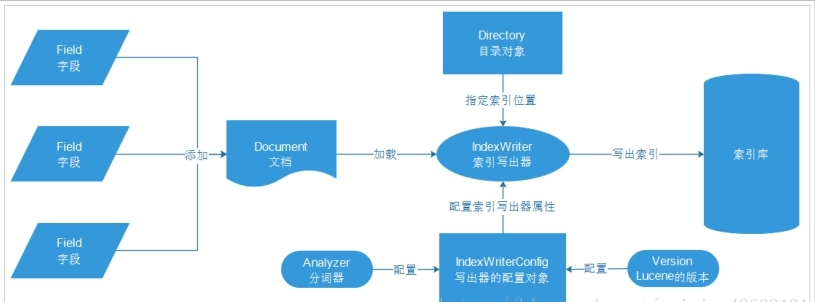
文档Document:数据库中一条具体的记录
字段Field:数据库中的每个字段
目录对象Directory:物理存储位置
写出器的配置对象:需要分词器和lucene的版本
话不多说coding... (哈哈激动)
导入依赖。。。
<!-- Lucene核心 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.7.2</version>
</dependency>
<!-- Lucene搜索查询相关 查询解析器-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.7.2</version>
</dependency>
<!-- Lucene分词器相关 基本分词器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.7.2</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>4.7.2</version>
</dependency>
<!-- Lucene分词器相关 ik-->
<!-- https://mvnrepository.com/artifact/com.janeluo/ikanalyzer -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
创建索引代码实现。。。
package com.Lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/**
* created by wudeming on 2019/10/13.
*/
public class LuceneIndexDemo {
public static void main(String[] args) {
// Lucene Document的域名
String fieldName = "nan";
String text = "";
// 建立5条索引
text = "特步男鞋运动鞋2019夏季新款网面透气休闲鞋秋季小白鞋跑步鞋男";
doIndex(fieldName, text);
text = "正品#全球购#人肉代#阿玛尼生姜高光替代款!DOUBLE GLEAM火起来真的不是没有道理,上脸真的太好看啦,是很闪很有存在感的高光爆炸热款,需要的私聊,少量!";
doIndex(fieldName, text);
text = "#专业代购#全球购#只做正品#爆款老前辈,阿玛尼红色气垫粉底,主打轻薄透气妆感,喜欢自然妆效的小伙伴一定要购入啊!轻薄不一定就不遮瑕,遮瑕适中,打造纹理肌肤最新时尚,你值得尝试,遮瑕也许不厉害,但妆感高级。色号齐全,可以调货,需要的私我。#只做真货#拒绝假货#";
doIndex(fieldName, text);
text = "Moncler 蒙口黑色羽绒服,女款, bandama 、 黑色0码收图,其他的尺码待查";
doIndex(fieldName, text);
text = "在澳洲的小伙伴赶紧联系我鸭~我需要十瓶这个伊索香芹籽精华,要澳洲专柜带发票喔,或者最近要去澳洲的小伙伴也可以(要出示购物小视频)。#香港或者国内商家勿扰,只要澳洲本地专柜人肉购入#(价格私聊)";
doIndex(fieldName, text);
}
/**
*
* @param fieldName 文本标题
* @param text 文本内容
*/
private static void doIndex(String fieldName, String text) {
//1 创建文档对象
// 2 创建存储目录
//3 创建分词器
//4 创建索引写入器的配置对象
//5 创建索引写入器对象
//6 将文档交给索引写入器
//7 提交
//8 关闭
// 实例化Analyzer分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);
// 实例化IKAnalyzer分词器
// Analyzer iKAnalyzer = new IKAnalyzer();
//索引目录
Directory directory = null;
//写对象
IndexWriter iwriter;
try {
//创建文档对象
Document doc = new Document();
// 索引目录 指定索引在硬盘中的位置 创建存储目录
directory = new SimpleFSDirectory(new File("E://test/lucene_index"));
// 配置IndexWriterConfig 参数:LUCENE版本 分词器
IndexWriterConfig iwConfig = new IndexWriterConfig(Version.LUCENE_47, analyzer);
//设置打开方式: IndexWriterConfig.OpenMode.APPEND 会在索引库的基础上追加索引
// IndexWriterConfig.OpenMode.CREATE 会清空原来的数据在提交 这里我选择了新建或追加
iwConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
// 创建索引写对象 参数:文件目录 索引配置对象
iwriter = new IndexWriter(directory, iwConfig);
//当前时间戳作为id
Long id = System.currentTimeMillis();
//DoubleField、FloatField、IntField、LongField、StringField、TextField这些子类一定会被创建索引,
// 但是不会被分词,而且不一定会被存储到文档列表。要通过构造函数中的参数Store来指定:如果Store.YES代表存储,Store.NO代表不存储
//StoreField一定会被存储,但是一定不创建索引
//创建并添加字段信息 参数:字段的名称 字段的值 是否储存 Field.Store.YES储存
doc.add(new StringField("ID", id + "", Field.Store.YES));
//参数:文件名 文件内容 是否储存; TextField创建索引并且分词 StringField 支撑件索引不会分词
doc.add(new TextField(fieldName, text, Field.Store.YES));
//写入文档
iwriter.addDocument(doc);
//提交
iwriter.commit();
//关闭流
iwriter.close();
System.out.println("建立索引成功:" + id);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
控制台输出
索引目录
查询索引数据代码实现...
package com.Lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/**
* created by wudemign on 2019/10/13.
*/
public class LuceneSearchDemo {
public static void main(String[] args) {
//1 创建读取目录对象
// 2 创建索引读取工具
// 3 创建索引搜索工具
// 4 创建查询解析器
// 5 创建查询对象
// 6 搜索数据
// 7 各种操作
// Lucene Document的域名
String fieldName = "nan";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);
Directory directory = null;
IndexReader ireader = null;
IndexSearcher isearcher;
try {
//索引目录
directory = new SimpleFSDirectory(new File("E://test/lucene_index"));
// 配置IndexWriterConfig
IndexWriterConfig iwConfig = new IndexWriterConfig(Version.LUCENE_47, analyzer);
iwConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
// 搜索过程**********************************
// 实例化搜索器
ireader = DirectoryReader.open(directory);
isearcher = new IndexSearcher(ireader);
String keyword = "特步";
// 使用QueryParser查询分析器构造Query对象
QueryParser qp = new QueryParser(Version.LUCENE_47, fieldName, analyzer);
qp.setDefaultOperator(QueryParser.OR_OPERATOR); // and or 跟数据库查询语法类似
Query query = qp.parse(keyword);
System.out.println("Query = " + query);
//查找的数量
int num = 2;
// 返回的结果是 按照匹配度排名得分前num名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。
TopDocs topDocs = isearcher.search(query, num);
System.out.println("命中:" + topDocs.totalHits);
// 遍历输出结果
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = 0; i < topDocs.totalHits; i++) {
if (i == num) break;
Document targetDoc = isearcher.doc(scoreDocs[i].doc);
System.out.println("内容:" + targetDoc.toString());
}
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (ireader != null) {
try {
ireader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
控制台输出

修改索引数据代码实现...
package com.Lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/**
* * 注意:
* 1:Lucene修改功能底层会先删除,再把新的文档添加。
* 2:修改功能会根据Term进行匹配,所有匹配到的都会被删除。这样不好
* 3:因此,一般我们修改时,都会根据一个唯一不重复字段进行匹配修改。例如ID
* 4:但是词条搜索,要求ID必须是字符串。如果不是,这个方法就不能用。
* 如果ID是数值类型,我们不能直接去修改。可以先手动删除deleteDocuments(数值范围查询锁定ID),再添加。
* created by wudemign on 2019/10/13.
*/
public class LuceneUpdateDemo {
public static void main(String[] args) {
//1 创建索引目录
//2 创建索引写入器配置对象
//3 创建索引写入器
//4 创建文档数据
//5 修改
//6 提交
//7 关闭
// 实例化IKAnalyzer分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);
Directory directory = null;
IndexWriter iwriter;
try {
// 索引目录
directory = new SimpleFSDirectory(new File("E://test/lucene_index"));
// 配置IndexWriterConfig
IndexWriterConfig iwConfig = new IndexWriterConfig(Version.LUCENE_47, analyzer);
iwConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
iwriter = new IndexWriter(directory, iwConfig);
// 写入索引
Document doc = new Document();
//索引ID
String id = "1571294471827";
doc.add(new StringField("ID", id, Field.Store.YES));
doc.add(new TextField("nan", "更新文档后->安踏男鞋运动鞋2019夏季新款网面透气休闲鞋秋季小白鞋跑步鞋男", Field.Store.YES));
//先根据Term ID 删除,在建立新的索引
iwriter.updateDocument(new Term("ID", id), doc);
iwriter.close();
System.out.println("更新索引成功:" + id);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
控制台输出
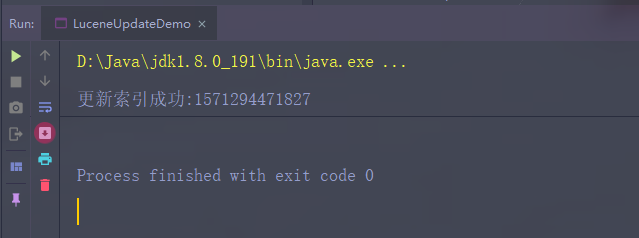
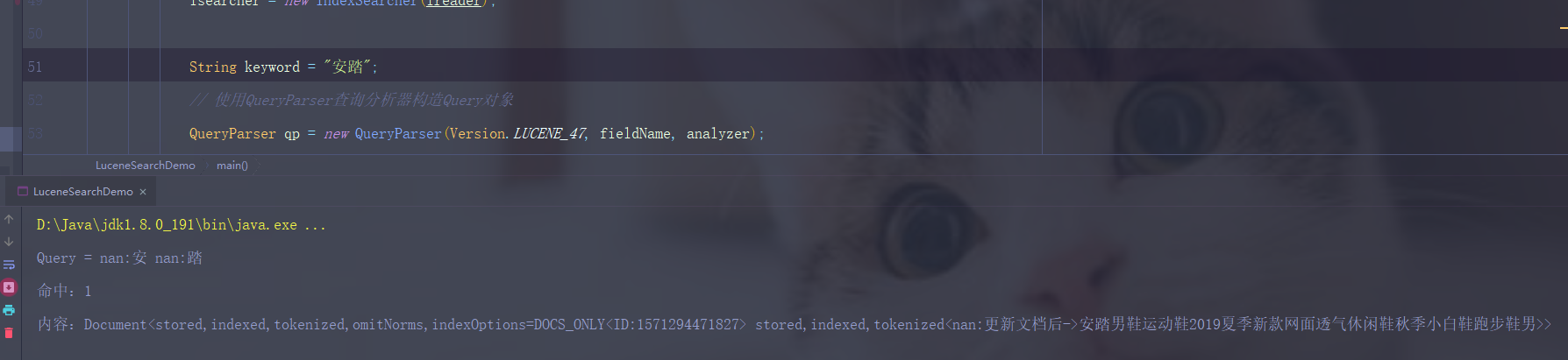
查看更新的数据能否查到
删除索引数据代码实现...
package com.Lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.*;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/*
* 演示:删除索引
* 注意:
* 一般,为了进行精确删除,我们会根据唯一字段来删除。比如ID
* 如果是用Term删除,要求ID也必须是字符串类型!
* created by wudemign on 2019/10/13.
*/
public class LuceneDeleteDemo {
public static void main(String[] args) {
//1 创建文档对象目录
//2 创建索引写入器配置对象
//3 创建索引写入器
//4 删除
//5 提交
//6 关闭
// Lucene Document的域名
String fieldName = "nan";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_47);
Directory directory = null;
IndexReader ireader = null;
IndexSearcher isearcher;
IndexWriter iwriter = null;
try {
//索引目录
directory = new SimpleFSDirectory(new File("E://test/lucene_index"));
// 配置IndexWriterConfig 创建配置对象
IndexWriterConfig iwConfig = new IndexWriterConfig(Version.LUCENE_47, analyzer);
iwConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
ireader = DirectoryReader.open(directory);
// 创建索引写出工具
iwriter = new IndexWriter(directory, iwConfig);
// 根据词条进行删除
iwriter.deleteDocuments(new Term("ID", "1571294471827"));
// 根据query对象删除,如果ID是数值类型,那么我们可以用数值范围查询锁定一个具体的ID
// Query query = NumericRangeQuery.newLongRange("id", 1571294471827, 1571294471827, true, true);
// writer.deleteDocuments(query);
//使用IndexWriter进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,
// 当IndexWriter.Commit()或IndexWriter.Close()时,删除操作才会被真正执行。
iwriter.commit();
iwriter.close();
ireader.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
搜索下看在不在。。
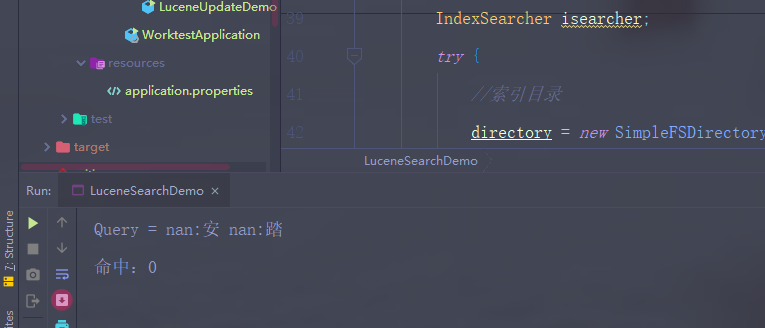
以上是在学习中的呆萌。。。 只是其中的简单的增删改查