
前言
flink 1.14之后,就提供了新的source架构,并且将在2.0之后抛弃之前的SourceFunction和InputFormat。官方地址 https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/dev/datastream/sources/ 。
很多资料都是介绍新架构的优点,运行机制等,但是目前还没找到介绍如何开发自定义Source的案例。大部分工具官方都会开发的connector应该都会跟进升级到新架构,一般来说,我们不需要自己开发,但是对于很多私有化场景总归免不了会遇到需要自定义Source的情况,这里我们就用一个自定义的MysqlSource简单介绍下如何自定义开发Source。
官方介绍
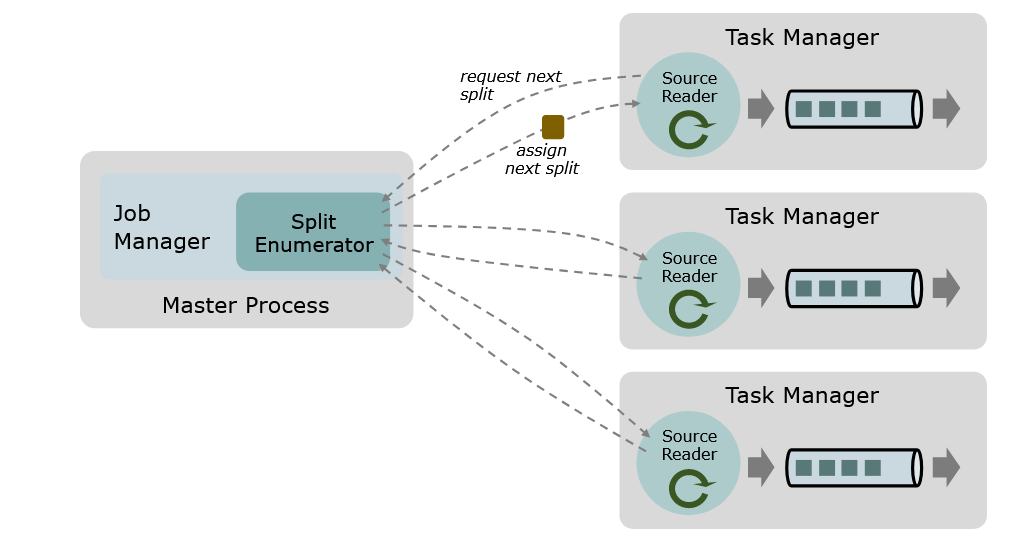
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
- 分片(Split)是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
- 源阅读器(SourceReader)会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的 SourceOperators 并行运行,并产生并行的事件流/记录流。
- 分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
开发我们的JdbcSource实现
添加依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.36</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.42</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.32</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.18.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.18.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.18.1</version>
</dependency>工程结构

文件说明

下面按照思路,看看具体实现
- 创建一个分片 JdbcSourceSplit,数据读取的分片,我们按照表进行划分
/**
* 定义一个分片,默认就是根据表进行分
*/
@Data
public class JdbcSourceSplit implements SourceSplit, Serializable {
private String splitId;
public JdbcSourceSplit(String splitId) {
this.splitId = splitId;
}
@Override
public String splitId() {
return splitId;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
JdbcSourceSplit that = (JdbcSourceSplit) o;
return Objects.equals(splitId, that.splitId);
}
@Override
public int hashCode() {
return Objects.hash(splitId);
}
}2. 创建一个类JdbcSourceSplitState,记录分片的状态
/**
* 记录分片的状态
*/
public class JdbcSourceSplitState {
private final JdbcSourceSplit split;
public JdbcSourceSplitState(JdbcSourceSplit split){
this.split = split;
}
public JdbcSourceSplit toJdbcSourceSplit(){
return split;
}
}3. 分片序列化类JdbcSourceSplitSerializer, 由于在作业中传递分片信息都是需要序列化和分序列化的,这里我们定义一个序列化处理器,里面的序列化和分序列化用的是fastjson2实现的,主要是满足对byte[]的转换。
/**
* 分片序列化类
*/
public class JdbcSourceSplitSerializer implements SimpleVersionedSerializer<JdbcSourceSplit> {
public static final JdbcSourceSplitSerializer INSTANCE = new JdbcSourceSplitSerializer();
@Override
public int getVersion() {
return 0;
}
@Override
public byte[] serialize(JdbcSourceSplit obj) throws IOException {
return JSON.toJSONBytes(obj);
}
@Override
public JdbcSourceSplit deserialize(int version, byte[] serialized) throws IOException {
return JSON.parseObject(serialized, JdbcSourceSplit.class);
}
}4. 定义反序列化接口JdbcDeserializationSchema,读取到的数据类型和最终返回的数据类型可能是不一样的,最终需要进行反序列化之后才返回。
/**
* 输出反序列化的接口
*
* @param <T>
*/
public interface JdbcDeserializationSchema<T> extends Serializable, ResultTypeQueryable<T> {
T deserialize(Row record) throws Exception;
}5. JdbcRecordEmitter 行数据发射器
/**
* 行数据发射器
* 工作主要就是用来做反序列化,将外部系统当中的数据格式转换成下游当中的一些数据格式。
*
* @param <T>
*/
public class JdbcRecordEmitter<T> implements RecordEmitter<Row, T, JdbcSourceSplitState> {
private final JdbcDeserializationSchema<T> deserializationSchema;
public JdbcRecordEmitter(JdbcDeserializationSchema<T> deserializationSchema) {
this.deserializationSchema = deserializationSchema;
}
/**
* 发射数据
* 得到的数据进行反序列化,然后,加入到 SourceOutput 对象中,由于后续的操作
*/
@Override
public void emitRecord(Row element, SourceOutput<T> output, JdbcSourceSplitState splitState) throws Exception {
T deserialize = deserializationSchema.deserialize(element);
if (deserialize != null) {
output.collect(deserialize);
}
}
}6. 源分片读取器,执行分片的读取操作
/**
* 分片读取,读取数据库中表的数据
*/
@Slf4j
public class JdbcSourceSplitReader implements SplitReader<Row, JdbcSourceSplit> {
private JdbcConnOptions connectionOptions;
private boolean closed = false;
private boolean finished = false;
private JdbcSourceSplit currentSplit;
private Connection connection;
public JdbcSourceSplitReader(
JdbcConnOptions connectionOptions
) {
this.connectionOptions = connectionOptions;
}
/**
* 读取数据,读取完之后,标记分片完成
*
* @return
* @throws IOException
*/
@Override
public RecordsWithSplitIds<Row> fetch() throws IOException {
log.info("fetch data");
if (closed) {
throw new IllegalStateException("Cannot fetch records from a closed split reader");
}
RecordsBySplits.Builder<Row> builder = new RecordsBySplits.Builder<>();
if (currentSplit == null) {
return builder.build();
}
try {
connection = createConnection();
ResultSet resultSet = connection.createStatement().executeQuery("select * from " + connectionOptions.getTable());
while (resultSet.next()) {
ResultSetMetaData metaData = resultSet.getMetaData();
Row row = new Row(metaData.getColumnCount());
for (int i = 0; i < row.getArity(); i++) {
String columnName = metaData.getColumnName(i + 1);
Object value = resultSet.getObject(i + 1);
row.setField(i, value); // 注意Row的索引是从0开始的
}
builder.add(currentSplit, row);
}
builder.addFinishedSplit(currentSplit.splitId());
finished = true;
return builder.build();
} catch (Exception e) {
throw new IOException("Scan records form db failed", e);
} finally {
if (finished) {
closeConnection();
}
}
}
/**
* 处理新增的分片
*
* @param splitsChanges
*/
@Override
public void handleSplitsChanges(SplitsChange<JdbcSourceSplit> splitsChanges) {
log.debug("Handle split changes {}", splitsChanges);
if (!(splitsChanges instanceof SplitsAddition)) { //如果不是新增分片则报异常
throw new UnsupportedOperationException(
String.format(
"The SplitChange type of %s is not supported.",
splitsChanges.getClass()));
}
JdbcSourceSplit sourceSplit = splitsChanges.splits().get(0);
if (!(sourceSplit instanceof JdbcSourceSplit)) {
throw new UnsupportedOperationException(
String.format(
"The SourceSplit type of %s is not supported.",
sourceSplit.getClass()));
}
this.currentSplit = (JdbcSourceSplit) sourceSplit;
this.finished = false;
}
@Override
public void wakeUp() {
}
@Override
public void close() throws Exception {
this.closed = true;
closeConnection();
}
public Connection createConnection() throws SQLException {
if (connection != null) {
return connection;
}
return DriverManager.getConnection(connectionOptions.getUrl(), connectionOptions.getUsername(), connectionOptions.getPassword());
}
public void closeConnection() {
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
log.error("close connection failed", e);
}
}
}
}
7. JdbcSourceReaderContext 源读取器上下文,可以对SourceReaderContext进行一些封装
public class JdbcSourceReaderContext implements SourceReaderContext {
private final SourceReaderContext readerContext;
private final AtomicInteger readCount = new AtomicInteger(0);
public JdbcSourceReaderContext(SourceReaderContext readerContext) {
this.readerContext = readerContext;
}
@Override
public SourceReaderMetricGroup metricGroup() {
return readerContext.metricGroup();
}
@Override
public Configuration getConfiguration() {
return readerContext.getConfiguration();
}
@Override
public String getLocalHostName() {
return readerContext.getLocalHostName();
}
@Override
public int getIndexOfSubtask() {
return readerContext.getIndexOfSubtask();
}
@Override
public void sendSplitRequest() {
readerContext.sendSplitRequest();
}
@Override
public void sendSourceEventToCoordinator(SourceEvent sourceEvent) {
readerContext.sendSourceEventToCoordinator(sourceEvent);
}
@Override
public UserCodeClassLoader getUserCodeClassLoader() {
return readerContext.getUserCodeClassLoader();
}
}8. JdbcSourceReader 源读取器,官方推荐继承SourceReaderBase实现,可以减少很多重复工作。
@Slf4j
public class JdbcSourceReader<OUT> extends SingleThreadMultiplexSourceReaderBase<Row, OUT, JdbcSourceSplit, JdbcSourceSplitState> {
public JdbcSourceReader(
FutureCompletingBlockingQueue<RecordsWithSplitIds<Row>> elementQueue,
Supplier<SplitReader<Row, JdbcSourceSplit>> splitReaderSupplier,
RecordEmitter<Row, OUT, JdbcSourceSplitState> recordEmitter,
JdbcSourceReaderContext context
) {
super(
elementQueue,
new SingleThreadFetcherManager<>(elementQueue, splitReaderSupplier),
recordEmitter,
context.getConfiguration(),
context
);
}
@Override
public void start() {
if (getNumberOfCurrentlyAssignedSplits() == 0) {
context.sendSplitRequest();
}
}
@Override
protected void onSplitFinished(Map<String, JdbcSourceSplitState> finishedSplitIds) {
for (JdbcSourceSplitState splitState : finishedSplitIds.values()) {
JdbcSourceSplit sourceSplit = splitState.toJdbcSourceSplit();
log.info("Split {} is finished.", sourceSplit.splitId());
}
context.sendSplitRequest();
}
/**
* 初始化分片状态
* @param split a newly added split.
* @return
*/
@Override
protected JdbcSourceSplitState initializedState(JdbcSourceSplit split) {
return new JdbcSourceSplitState(split);
}
@Override
protected JdbcSourceSplit toSplitType(String splitId, JdbcSourceSplitState splitState) {
return splitState.toJdbcSourceSplit();
}
}9.JdbcSourceEnumState 定义一个状态类,用于记录处理状态
/**
* 定义一个状态类,用于记录处理状态
*/
@Data
public class JdbcSourceEnumState implements Serializable {
private List<String> remainingTables; //剩余待处理的表
private List<String> alreadyProcessedTables; //已经处理过的表
private List<JdbcSourceSplit> remainingSplits; //剩余待处理的split
private Map<String,JdbcSourceSplit> assignedSplits; //分配的split
private final boolean initialized;
public JdbcSourceEnumState(List<String> remainingTables, List<String> alreadyProcessedTables, List<JdbcSourceSplit> remainingSplits, Map<String,JdbcSourceSplit> assignedSplits, boolean initialized) {
this.remainingTables = remainingTables;
this.alreadyProcessedTables = alreadyProcessedTables;
this.remainingSplits = remainingSplits;
this.assignedSplits = assignedSplits;
this.initialized = initialized;
}
public List<String> getRemainingTables() {
return remainingTables;
}
public List<String> getAlreadyProcessedTables() {
return alreadyProcessedTables;
}
public List<JdbcSourceSplit> getRemainingSplits() {
return remainingSplits;
}
public Map<String,JdbcSourceSplit> getAssignedSplits() {
return assignedSplits;
}
public boolean isInitialized() {
return initialized;
}
public static JdbcSourceEnumState initialState(){
return new JdbcSourceEnumState(new ArrayList<>(),new ArrayList<>(),new ArrayList<>(),new HashMap<>(),false);
}
}10.JdbcSourceEnumStateSerializer 分片枚举起状态序列化工具
/**
* 分片枚举器状态序列化类
*/
public class JdbcSourceEnumStateSerializer implements SimpleVersionedSerializer<JdbcSourceEnumState> {
public static final JdbcSourceEnumStateSerializer INSTANCE = new JdbcSourceEnumStateSerializer();
@Override
public int getVersion() {
return 0;
}
@Override
public byte[] serialize(JdbcSourceEnumState obj) throws IOException {
return JSON.toJSONBytes(obj);
}
@Override
public JdbcSourceEnumState deserialize(int version, byte[] serialized) throws IOException {
return JSON.parseObject(serialized, JdbcSourceEnumState.class);
}
}11. JdbcSplitAssigner 分片的实际执行类
/**
* 分片实际执行
*/
@Slf4j
public class JdbcSplitAssigner {
private final JdbcConnOptions connectionOptions;
private final LinkedList<String> remainingTables;
private final List<String> alreadyProcessedTables;
private final LinkedList<JdbcSourceSplit> remainingSplits;
private final Map<String, JdbcSourceSplit> assignedSplits;
private boolean initialized;
/**
* 分片枚举器的指定执行器(实际执行)
* @param connectionOptions
* @param sourceEnumState
*/
public JdbcSplitAssigner(
JdbcConnOptions connectionOptions,
JdbcSourceEnumState sourceEnumState) {
this.connectionOptions = connectionOptions;
this.remainingTables = new LinkedList<>(sourceEnumState.getRemainingTables());
this.remainingSplits = new LinkedList<>(sourceEnumState.getRemainingSplits());
this.alreadyProcessedTables = sourceEnumState.getAlreadyProcessedTables();
this.assignedSplits = sourceEnumState.getAssignedSplits();
this.initialized = sourceEnumState.isInitialized();
}
public void open() {
log.info("jdbc scan split assigner is opening.");
if (!initialized) {
String tableId =
String.format(
"%s.%s",
connectionOptions.getDatabase(), connectionOptions.getTable());
remainingTables.add(tableId);
this.initialized = true;
}
}
public Optional<JdbcSourceSplit> getNext() {
if (!remainingSplits.isEmpty()) {
JdbcSourceSplit split = remainingSplits.poll();
assignedSplits.put(split.splitId(), split);
return Optional.of(split);
} else {
String nextTable = remainingTables.poll();
if (nextTable != null) {
JdbcSourceSplit split = new JdbcSourceSplit(nextTable);
remainingSplits.add(split);
alreadyProcessedTables.add(nextTable);
return getNext();
} else {
return Optional.empty();
}
}
}
public void addSplitsBack(Collection<JdbcSourceSplit> splits) {
for (JdbcSourceSplit split : splits) {
remainingSplits.add(split);
assignedSplits.remove(split.splitId());
}
}
public JdbcSourceEnumState snapshotState(long checkpointId) {
return new JdbcSourceEnumState(
remainingTables,
alreadyProcessedTables,
remainingSplits,
assignedSplits,
initialized);
}
public boolean noMoreSplits() {
checkState(initialized, "The noMoreSplits method was called but not initialized.");
return remainingTables.isEmpty() && remainingSplits.isEmpty();
}
public void close() {
}
}12. JdbcSourceEnumerator 分片枚举器
/**
* 分片枚举器
*/
@Slf4j
public class JdbcSourceEnumerator implements SplitEnumerator<JdbcSourceSplit, JdbcSourceEnumState> {
private final Boundedness boundedness;
private final SplitEnumeratorContext<JdbcSourceSplit> context;
private final JdbcSplitAssigner splitAssigner;
private final TreeSet<Integer> readersAwaitingSplit;
public JdbcSourceEnumerator(
Boundedness boundedness,
SplitEnumeratorContext<JdbcSourceSplit> context,
JdbcSplitAssigner splitAssigner
) {
this.boundedness = boundedness;
this.context = context;
this.splitAssigner = splitAssigner;
this.readersAwaitingSplit = new TreeSet<>();
}
@Override
public void start() {
splitAssigner.open();
}
/**
* 处理分片请求
*/
@Override
public void handleSplitRequest(int subtaskId, @Nullable String requesterHostname) {
if (!context.registeredReaders().containsKey(subtaskId)) {
// reader failed between sending the request and now. skip this request.
return;
}
readersAwaitingSplit.add(subtaskId);
assignSplits();
}
@Override
public void addSplitsBack(List<JdbcSourceSplit> splits, int subtaskId) {
log.debug("Jdbc Source Enumerator adds splits back: {}", splits);
splitAssigner.addSplitsBack(splits);
}
@Override
public void addReader(int subtaskId) {
log.debug("Adding reader {} to JdbcSourceEnumerator.", subtaskId);
}
@Override
public JdbcSourceEnumState snapshotState(long checkpointId) throws Exception {
return splitAssigner.snapshotState(checkpointId);
}
@Override
public void close() throws IOException {
splitAssigner.close();
}
/**
* 处理分片,这里主要以表作为分片依据
*/
private void assignSplits() {
final Iterator<Integer> awaitingReader = readersAwaitingSplit.iterator();
while (awaitingReader.hasNext()) {
int nextAwaiting = awaitingReader.next();
if (!context.registeredReaders().containsKey(nextAwaiting)) {
awaitingReader.remove();
continue;
}
if (splitAssigner.noMoreSplits() && boundedness == Boundedness.BOUNDED) {
context.signalNoMoreSplits(nextAwaiting);
awaitingReader.remove();
log.info(
"All scan splits have been assigned, closing idle reader {}", nextAwaiting);
continue;
}
Optional<JdbcSourceSplit> split = splitAssigner.getNext();
if (split.isPresent()) {
JdbcSourceSplit jdbcSourceSplit = split.get();
context.assignSplit(jdbcSourceSplit, nextAwaiting);
awaitingReader.remove();
log.info("Assign split {} to subtask {}", jdbcSourceSplit, nextAwaiting);
break;
} else {
break;
}
}
}
}13. JdbcSource 源阅读器
public class JdbcSource<OUT> implements Source<OUT, JdbcSourceSplit, JdbcSourceEnumState>, ResultTypeQueryable<OUT> {
private final JdbcConnOptions connectionOptions;
private final Boundedness boundedness;
private final JdbcDeserializationSchema<OUT> jdbcDeserializationSchema;
public JdbcSource(
JdbcConnOptions connectionOptions,
JdbcDeserializationSchema<OUT> jdbcDeserializationSchema
) {
this.connectionOptions = connectionOptions;
this.jdbcDeserializationSchema = jdbcDeserializationSchema;
this.boundedness = Boundedness.BOUNDED;
}
@Override
public Boundedness getBoundedness() {
return Boundedness.BOUNDED;
}
/**
* 创建分片枚举器
*
* @param enumContext The {@link SplitEnumeratorContext context} for the split enumerator.
* @return
* @throws Exception
*/
@Override
public SplitEnumerator<JdbcSourceSplit, JdbcSourceEnumState> createEnumerator(SplitEnumeratorContext<JdbcSourceSplit> enumContext) throws Exception {
JdbcSourceEnumState sourceEnumState = JdbcSourceEnumState.initialState();
JdbcSplitAssigner splitAssigner = new JdbcSplitAssigner(connectionOptions, sourceEnumState);
return new JdbcSourceEnumerator(this.boundedness, enumContext, splitAssigner);
}
/**
* 重置分片枚举器
*/
@Override
public SplitEnumerator<JdbcSourceSplit, JdbcSourceEnumState> restoreEnumerator(SplitEnumeratorContext<JdbcSourceSplit> enumContext, JdbcSourceEnumState checkpoint) throws Exception {
JdbcSourceEnumState sourceEnumState = JdbcSourceEnumState.initialState();
JdbcSplitAssigner splitAssigner = new JdbcSplitAssigner(connectionOptions, sourceEnumState);
return new JdbcSourceEnumerator(this.boundedness, enumContext, splitAssigner);
}
/**
* 分片的序列化器
*
* @return
*/
@Override
public SimpleVersionedSerializer<JdbcSourceSplit> getSplitSerializer() {
return JdbcSourceSplitSerializer.INSTANCE;
}
/**
* 处理状态的序列化器
*
* @return
*/
@Override
public SimpleVersionedSerializer<JdbcSourceEnumState> getEnumeratorCheckpointSerializer() {
return JdbcSourceEnumStateSerializer.INSTANCE;
}
/**
* 创建源阅读器
*
*/
@Override
public SourceReader<OUT, JdbcSourceSplit> createReader(SourceReaderContext readerContext) throws Exception {
FutureCompletingBlockingQueue<RecordsWithSplitIds<Row>> elementsQueue =
new FutureCompletingBlockingQueue<>();
JdbcSourceReaderContext jdbcSourceReaderContext = new JdbcSourceReaderContext(readerContext);
Supplier<SplitReader<Row, JdbcSourceSplit>> splitReaderSupplier = () -> new JdbcSourceSplitReader(
connectionOptions
);
return new JdbcSourceReader<>(elementsQueue, splitReaderSupplier, new JdbcRecordEmitter<>(jdbcDeserializationSchema), jdbcSourceReaderContext);
}
@Override
public TypeInformation<OUT> getProducedType() {
return jdbcDeserializationSchema.getProducedType();
}
}到这里,Source 代码层面算是开发完成了。
测试
下面我们做个测试,从一个表向另外一个表迁移数据。
1.创建表user
create table user
(
id varchar(64) null
);然后随便插入两条数据1,2
再创建一个同样结构的user_sink表
2. 行数据的反序列化实现类
/**
* 行数据的反序列化实现类
*/
private static class JdbcJsonDeserializationSchema implements JdbcDeserializationSchema<Row> {
@Override
public TypeInformation<Row> getProducedType() {
return new RowTypeInfo(Types.STRING);
}
@Override
public Row deserialize(Row record) {
return record;
}
}3. 测试代码
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.2-1.18</version>
</dependency>代码实现
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
JdbcSource<Row> jdbcSource = new JdbcSource<>(
JdbcConnOptions.builder()
.url("jdbc:mysql://xxxx:3306/flink-demo")
.username("flink_demo")
.password("flink_demo")
.database("flink-demo")
.table("user")
.build(),
new JdbcJsonDeserializationSchema());
DataStream<Row> dataStream = env.fromSource(jdbcSource, WatermarkStrategy.noWatermarks(), "jdbc sources");
dataStream.addSink(JdbcSink.sink(
"insert into user_sink (id) values (?)",
(ps, t) -> {
ps.setString(1,t.getFieldAs(0));
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://xxxx:3306/flink-demo")
.withUsername("flink_demo")
.withPassword("flink_demo")
.withDriverName("com.mysql.cj.jdbc.Driver")
.build()
));
env.execute();
}4. 运行结果
顺利将user表中的数据同步到user_sink表
以上就是一个自定义Source的实现,具体的细节可以通过阅读flink源码进行深入详细的了解。