背景
近几年随着降本增效这个大背景,大风向的吹动下。在大规模日志分析场景下,原本由Elasticsearch为主要存储,现在受Elasticsearch成本巨高的影响,很多公司将目光瞄向了Clickhouse。其中,携程,字节,B站等公司已经在生产中大规模落地了Clickhouse。
在2023年年初的版本中,Clickhouse官方推出了大家期待已久的,Inverted倒排索引,今天我们拿实际的生产数据,来看看Clickhouse在分词场景的表现究竟如何
前置
物理集群 3台8C32G100G普通盘
写入程序 10个并发度,10000一个批次的写入
Clickhouse版本2023.12
各索引详细对比
无分词索引
CREATE TABLE test_info_log.info_log
(
`logTime` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`companyId` UInt32 CODEC(ZSTD(1)),
`appName` LowCardinality(String) CODEC(ZSTD(1)),
`content` LowCardinality(String) CODEC(ZSTD(1))
)
ENGINE = MergeTree
PARTITION BY toDate(logTime)
ORDER BY logTime
SETTINGS index_granularity = 8192
在不设置分词索引的情况下,进行压力测试,结果如下
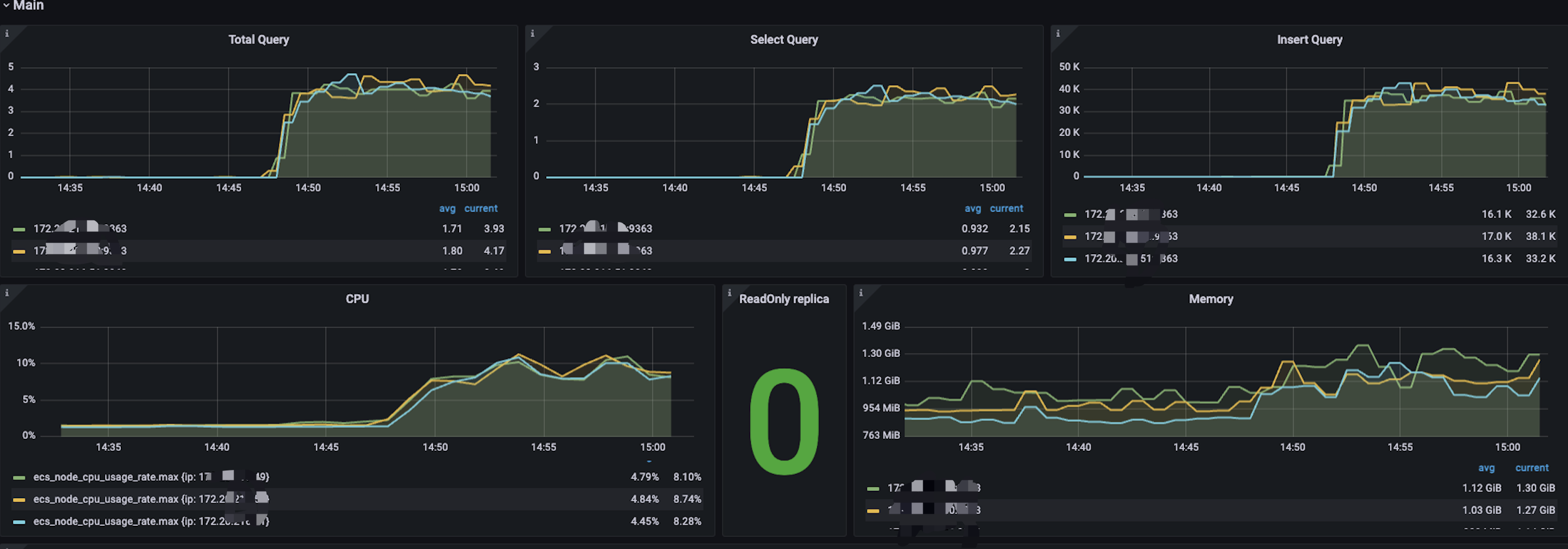
我们以不分词的时候的数据写入情况建立标准
-
单节点每秒的写入量在3W5左右
-
内存,CPU处于低位,整体集群负载不高
在了解Clickhouse分词前先看下,bloom Filter,clickhouse的分词都是基于bloom Filter来做的,我们借助于这个工具,来找到最佳合适的bloom Filter的大小参数
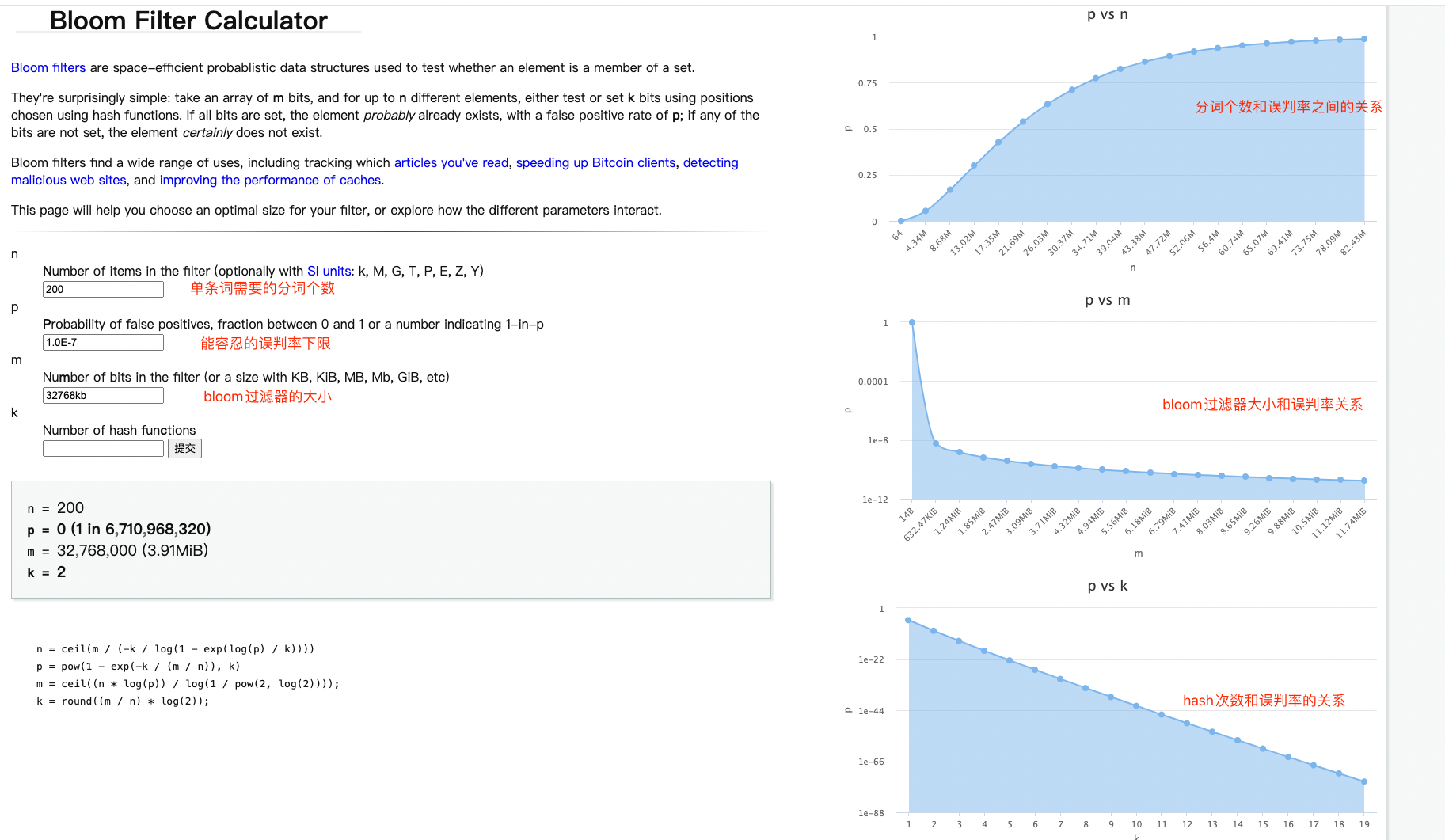
可以得到部分结论:
-
bloom过滤器越大,假阳性的概率越低,误判率也就越低
-
所需要的分词个数越多,则误判率也会增加,数据上来看64以内的是最好的,接近于0
下面来看具体的索引
tokenbf_v1索引
tokenbf_v1类似于bloom_filter索引,不同的在于tokenbf_v1先对指定字段进行token分词后再进行构建bloom_filter。token分词是指按照空格,标点符号,或者其他非字母数据进行分割。如”I am zhangsan“,分词出”I“,”am“,”zhangsan“。
tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed) 包含三个参数:
-
size_of_bloom_filter_in_bytes:bloom filter 大小,字节为单位;bloom filter 越大会有更少的假阳性但有更高的存储成本;
-
number_of_hash_functions:bloom filter 使用的散列函数数目,更多散列函数可能会减少假阳性,但有增加计算量;
-
random_seed:bloom filter 散列函数的随机种子;
ALTER TABLE za_info_log.info_log ADD INDEX idx_content content TYPE tokenbf_v1(32768, 2, 0)
GRANULARITY 16;-
性能情况
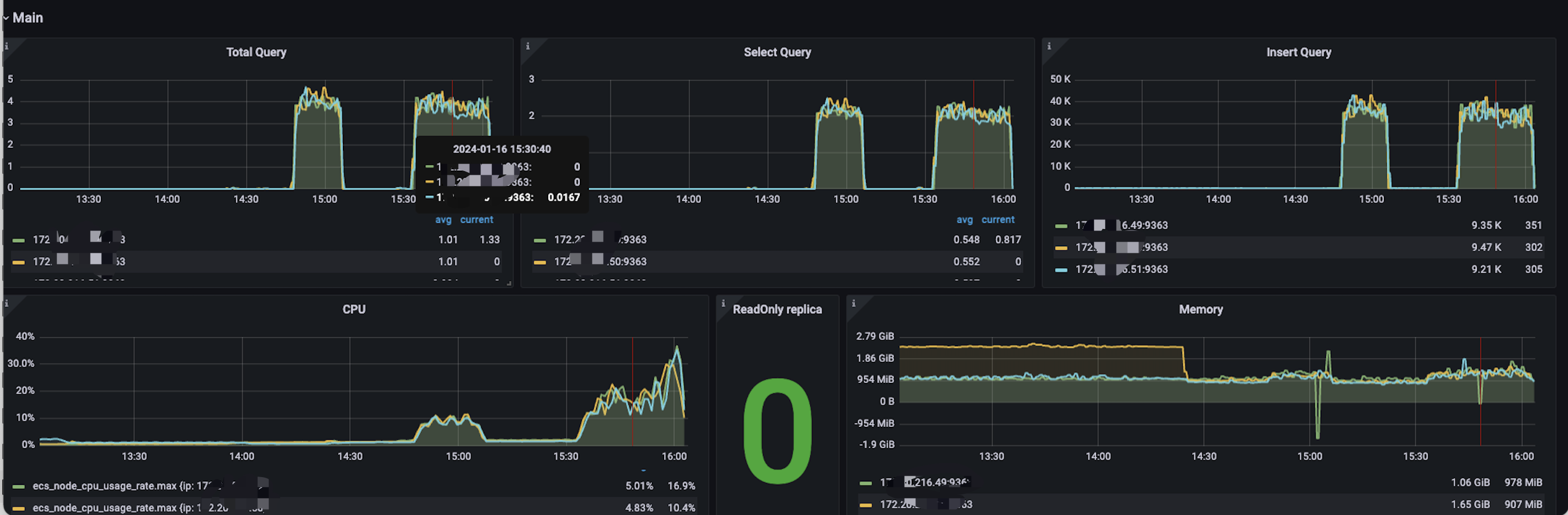
-
写入性能较不带分词相差无几
-
CPU负载提高一倍
-
压缩率

-
查询情况
总共9个parts分区
|
分词 |
查询情况 |
索引命中情况 |
结果说明 |
|---|---|---|---|
|
不带特殊符号,如_,"",- |
耗时 14.46秒 |
命中 |
跳过了3个分区,扫描6/9分区 |
|
带特殊字符 |
耗时: 17.08 |
未命中 |
扫描全部parts |
|
被冒号”“分割的字符 |
耗时: 14.071秒 |
命中 |
跳过了4个分区,扫描5/9 分区 |
|
中文 |
耗时: 17.92秒 |
未命中 |
扫描全部parts |
-
总结
-
tokenbf_v1 的分词是通过特殊字符做的分词,而带上特殊字符后,数据将扫描全表
-
带无规则数字字母的效率要比非数字字母的效果要好
ngrambf_v1索引
ngrambf_v1 索引类似于 tokenbf_v1 索引,不同在于 ngrambf_v1 采用 ngram 分词方式,常用于 like 等查询。基于 ngram 分词主要是按指定字符数目进行分割,如 “I am ‘zhangsan’” 则 ngram(2) 分割出 “I “、” a”、“am”、“m “、” '”、"‘i"、“im”、“mc” 与 “ci”,常用于没有空格分隔的语言,如中文。
-
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed) 包含四个参数,其中 n 为连词长度,即要索引的ngram的大小;其它参数同 tokenbf_v1一样
ALTER TABLE za_info_log.info_log ADD INDEX idx_content content TYPE
ngrambf_v1(4, 32768, 2, 0) GRANULARITY 16;-
性能机器指标

-
相较于tokenbf_v1 ,写入性能维持在2.8W左右,写入性能下降约20%
-
CPU,内存 较tokenbf_v1索引翻了一倍
-
压缩率
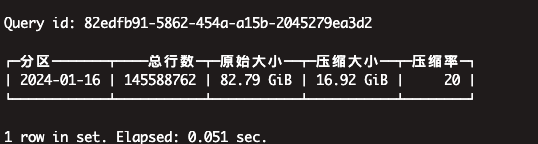
整体压缩率,磁盘占用率较tokenbf_v1,有1%的上升
inverted倒排索引
inverted是Clickhouse2023年新出的,这也是我们这次测试的重点。inverted顾名思义,倒排索引,他的实现方式和我们了解的ES等构建倒排的实现原理类似
倒排索引说明:
-
inverted的官方的说明是相较于tokenbf,ngrambf有1-8倍左右的性能提升
-
在使用上,inverted()说明
-
inverted(0) 或 inverted() 采用 token 分词方式;
-
inverted(N) 2 <= N <= 8,采用 ngram(N) 分词方式;
-
ALTER TABLE za_info_log.info_log ADD INDEX inv_idx(content) TYPE inverted(4) GRANULARITY 16;-
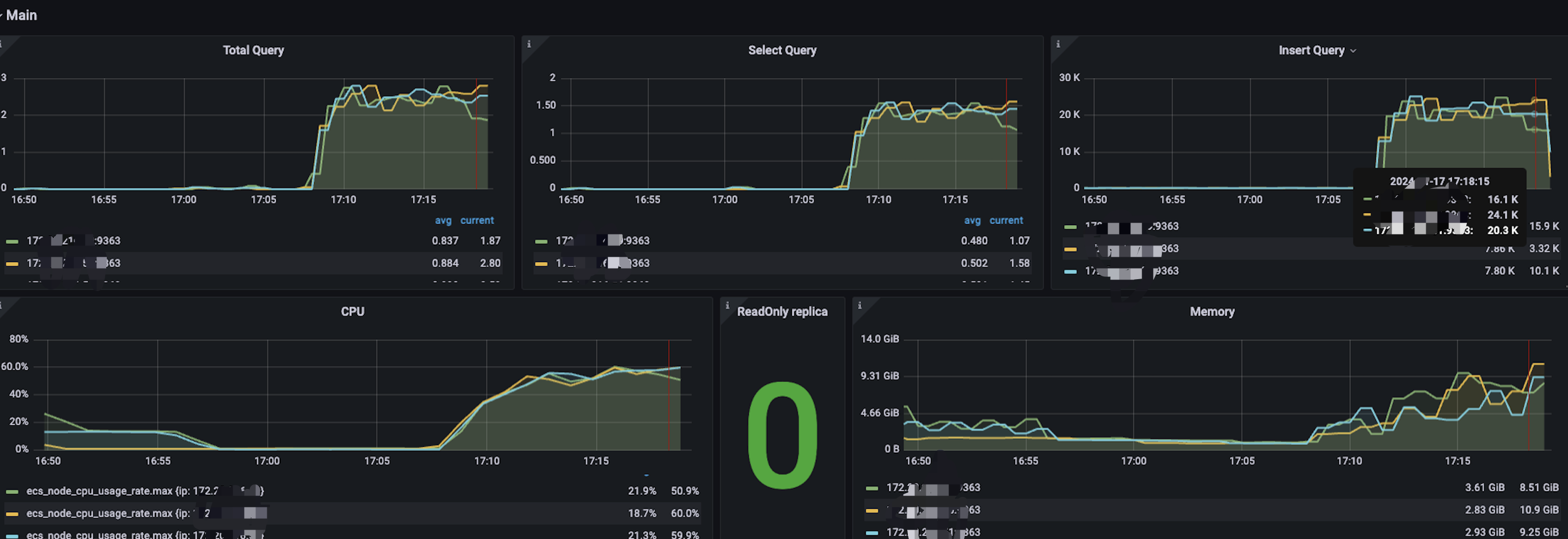
性能机器指标
Inverted() 不带参数,使用token进行分词的情况下
1. 写入性能较其他索引下降30%左右,单机写入均值在2W条左右/秒
2. CPU,内存负载较其他索引有较大幅度的增长,增长了2倍的负载
-
压缩率

-
查询情况
总22个parts分区
|
分词 |
查询情况 |
索引命中情况 |
结果说明 |
|---|---|---|---|
|
不带特殊符号,如_,"",- |
耗时 1.2秒 |
命中 |
跳过了20个parts |
|
带特殊字符 |
耗时: 19秒 |
未命中 |
扫描全部parts |
|
被冒号”“分割的字符 |
耗时: 1.883秒 |
命中 |
跳过了20个parts |
|
中文 |
耗时: 9.931秒 |
命中 |
跳过了1个parts |
总结
性能总结
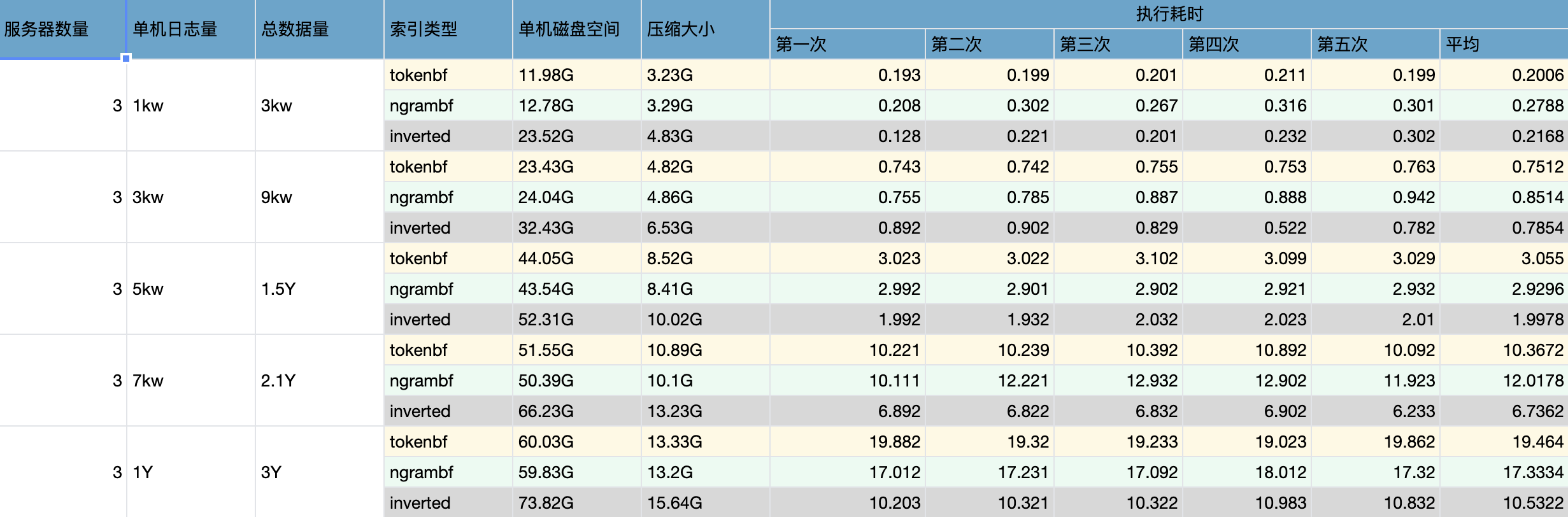
-
tokenbf和ngrambf索引在1.5亿级别的数据量的情况下,性能相差无几,磁盘压缩率占用量也无较大差别
-
在2Y级别,ngrambf索引略优于tokenbf索引
-
inverted索引的读取性能基本全面优于tokenbf,ngrambf索引
-
inverted索引的磁盘空间和CPU,内存等,在写入的时候均为tokenbf,ngrambf的两倍,更加机器资源
-
当inverted>0的时候,写入性能较不开索引下降2/3,CPU内存上涨3倍,当inverted使用tokenbf的时候,写入性能较不开索引下降1/4
功能总结
-
tokenbf不支持特殊字符的检索,当使用特殊字符时做模糊查询的时候,会扫描全部分区
-
ngrambf分词支持特殊字符,但是命中率较低,而且很依赖N的长度预设,非常难以把控
-
inverted索引,支持特殊字符和中文,但是会吃一倍的资源,也会影响20%左右的写入性能,查询性能较其他是最好的,有30%的查询性能提升