LangChain介绍:LangChain中文文档
LangChain 是一个开发由语言模型驱动的应用程序的框架。我们相信最强大和不同的应用程序不仅会通过 API 调用语言模型, 还会:
数据感知 : 将语言模型连接到其他数据源
具有代理性质 : 允许语言模型与其环境交互
为什么要实现本地知识库?
在信息时代,知识的生成和传播速度日益加快,对知识的管理和利用成为了企业和个人提升效率和竞争力的关键。随着人工智能和机器学习技术的快速发展,大语言模型应运而生,它们可以处理和生成自然语言文本,提供问答服务,生成内容以及在多个领域内协助决策等。然而,即便是最先进的大语言模型也存在局限性和痛点。因此,建立本地知识库,对于提升信息的获取、管理和应用效率,有着举足轻重的作用。
大语言模型的局限性和痛点
知识更新滞后性:大语言模型通常在训练时就确定了知识的上限。模型一旦部署,其内置知识就很难实时更新,这意味着最新的信息、数据和研究成果无法立即反映在模型应答中。
数据源的局限:模型的知识来自于训练数据,这些数据可能来自开放的互联网资源,而不是特定组织内部的专有或定制数据,导致答案可能缺乏特定上下文的精确性。
隐私和数据安全问题:模型训练和使用涉及海量数据,可能包含敏感信息,如何保障数据的隐私和安全成为一个挑战。
内容的准确性和可信度问题:虽然大语言模型可以生成流畅的文本,但不能保证所提供信息的真实性和准确性,需谨慎处理模型生成的内容。
泛化能力和个性化需求的冲突:大语言模型具有很好的泛化能力,但在处理特定领域或用户个性化需求时可能表现不尽如人意。
本地知识库的优点
针对上述痛点,本地知识库提供了以下优势:
即时更新和维护:本地知识库可以随时更新,确保用户能够接触到最新的信息和数据,从而做出更准确的判断和决策。
定制化和专业化:本地知识库可以根据特定组织或个人的需求进行定制化建设,包含行业特定的术语和数据,提高信息的相关性。
数据隐私与安全保护:通过建立本地知识库,可以实现数据的本地化管理,从而更好地控制数据的访问权限和保护信息的安全。
可信度和准确性:本地知识库可以由专业人士维护和审核,确保所含信息的准确性和可靠性,提高用户的信任度。
个性化服务:本地知识库可以根据用户的具体需求进行优化,提供更加个性化的服务,提升用户体验
虽然大语言模型在处理和生成自然语言文本方面表现出色,但因其存在更新滞后、数据源局限、隐私安全、准确性和个性化服务的挑战,本地知识库的建立显得至关重要。本地知识库能够提供更新迅速、高度定制化、安全可靠、准确可信以及个性化服务的优势,它是组织和个人在知识密集型社会中不可或缺的工具。通过建立和维护本地知识库,能够更好地支持决策制定,提升工作效率,加强竞争力。
什么是Embedding?
嵌入式模型的核心思想是将每个数据点映射到一个低维度的嵌入向量(embedding vector)中,使得相似的数据点在嵌入空间中距离接近。具体来说,嵌入向量是一个实数向量,通常包含几十到几百个元素,每个元素代表一个特征或语义信息,而不是像One-hot编码一样只有一个元素是1,其余都是0。
嵌入向量的生成通常使用神经网络进行训练,其中包括输入层、隐藏层和输出层。输入层接受原始的高维数据,如文本或图像等,隐藏层将其转化为嵌入向量,输出层将嵌入向量映射到所需的预测结果,如文本分类或图像识别等。
在训练嵌入式模型时,通常使用大量的数据样本进行训练,目的是通过学习数据样本之间的相似性和差异性,优化嵌入向量的表示。训练过程中,通常使用损失函数来度量嵌入向量的表示与真实值之间的差距,并通过反向传播算法来更新模型参数,使得模型能够更好地捕捉特征和语义信息。
实现本地知识库的逻辑
加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。

从文档处理角度来看,实现流程如下:

生成Embedding
文本切片
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入文本
loader = UnstructuredFileLoader("test.txt")
# 将文本转成 Document 对象
data = loader.load()
print(f'documents:{len(data)}')
# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:",len(split_docs))生成embedding
目前生成embedding有两种方式
1、直接使用OpenAIEmbeddings来生成Embedding数据
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import VectorDBQA
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.embeddings.openai import OpenAIEmbeddings
import IPython
import os
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 如果希望通过代理来访问可以配置上
# os.environ["OPENAI_API_BASE"] = os.getenv("OPENAI_API_BASE")
embeddings = OpenAIEmbeddings( )2、使用HuggingFaceEmbeddings来生成Embedding数据
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import IPython
import sentence_transformers
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"text2vec2":"uer/sbert-base-chinese-nli",
"text2vec3":"shibing624/text2vec-base-chinese",
}
EMBEDDING_MODEL = "text2vec3"
# 初始化 hugginFace 的 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL], )
embeddings.client = sentence_transformers.SentenceTransformer(
embeddings.model_name, device='mps')两种方式的差别:
OpenAIEmbeddings:
使用简单,并且效果比较好;
会消耗openai的token,特别是大段文本时,消耗的token还不少,如果知识库是比较固定的,可以考虑将每次生成的embedding做持久化,这样就不需要再调用openai了,可以大大节约token的消耗;
可能会有数据泄露的风险,如果是一些高度私密的数据,不建议直接调用。
HuggingFaceEmbeddings:
可以在HuggingFace上面选择各种sentence-similarity模型来进行实验,数据都是在本机上进行计算
需要一定的硬件支持,最好是有GPU支持,不然生成数据可能会非常慢
生成的向量效果可能不是很好,并且HuggingFace上的中文向量模型不是很多。
保存Embedding数据
有多种向量数据库选择,这里选择比较简单的Chroma,因为比较轻量,直接安装库就可使用。
from langchain.vectorstores import Chroma
# 初始化加载器
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/openai/news_test")
# 持久化
db.persist()持久化后,可以直接选择从持久化文件中加载,不需要再重新就可使用了,使用方式如下:
db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)从向量数据库查询4条相关的知识
# 初始化 prompt 对象
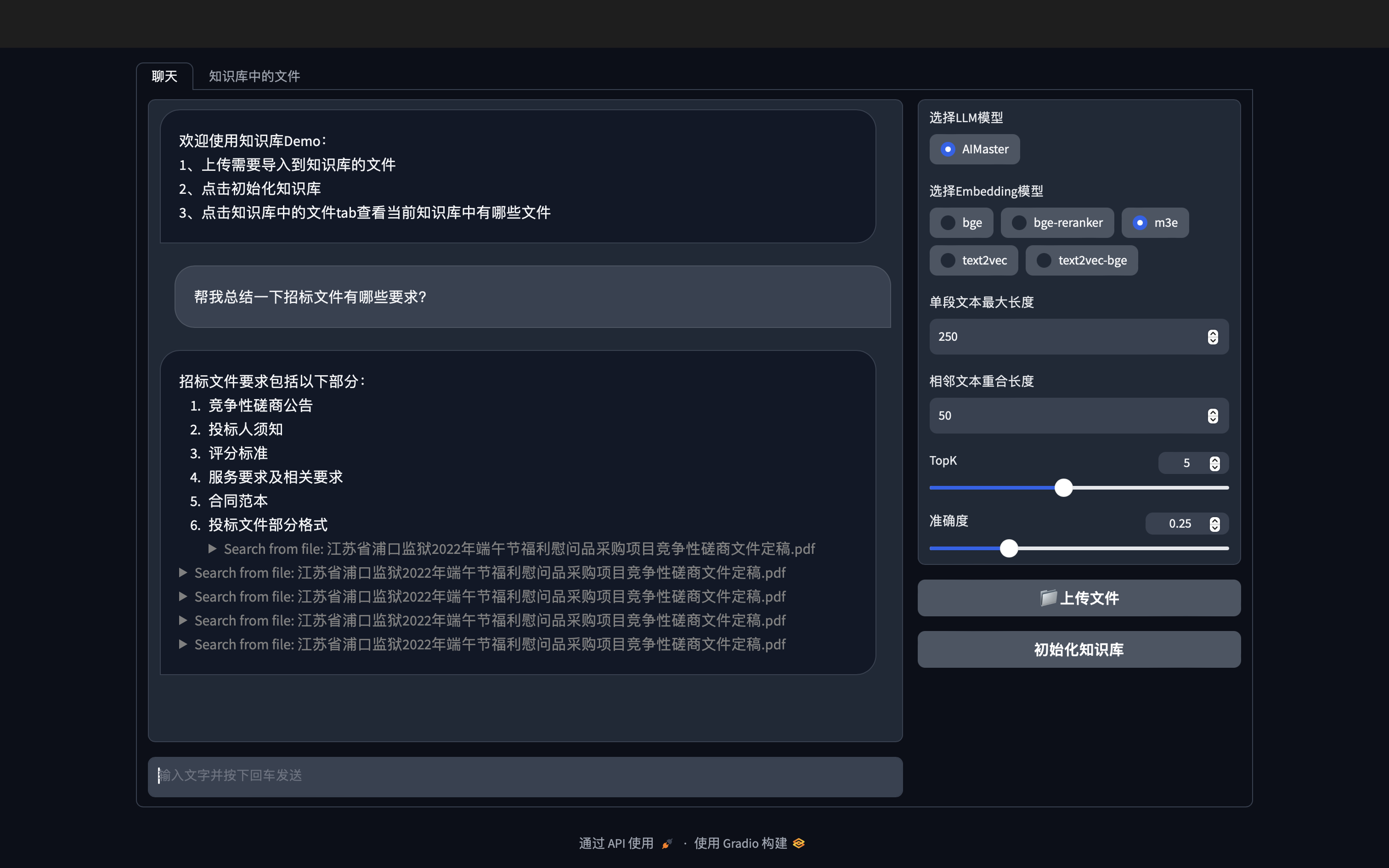
question = "2022年腾讯营收多少"
similarDocs = db.similarity_search(question, include_metadata=True,k=4)
[print(x) for x in similarDocs]接入ChatGLM来帮忙做总结和汇
from langchain.chains import RetrievalQA
import IPython
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=ChatGLM(temperature=0.1), chain_type="stuff", retriever=retriever)
# 进行问答
query = "2022年腾讯营收多少"
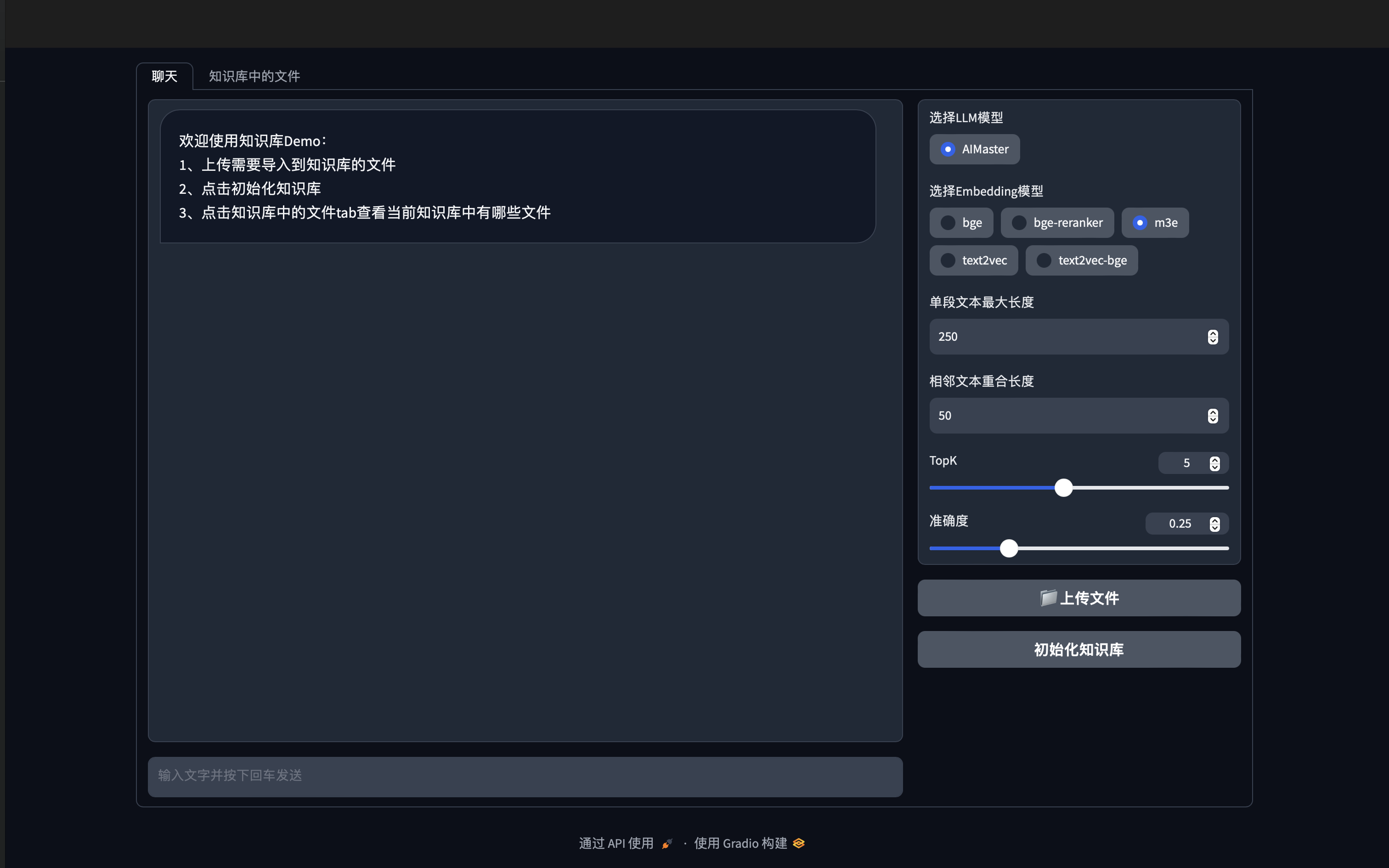
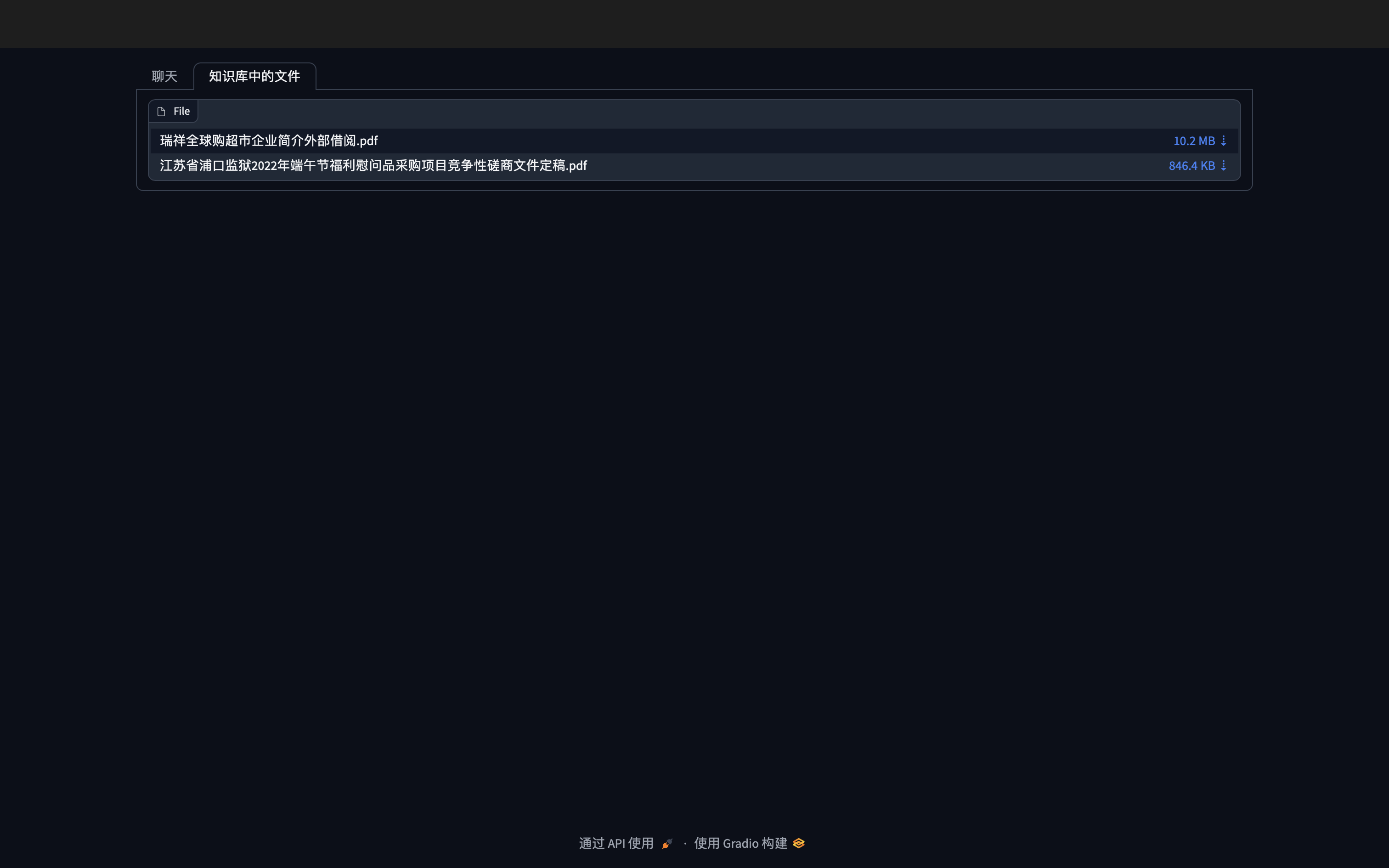
print(qa.run(query))Gradio图形Demo效果
总结
本文使用LangChain+ChatGLM来实现一个简单的基于本地知识库的问答系统,可以在完全不使用openai提供的api来完成本地知识库问答系统的搭建,如果有需要做本地私有化知识库问答系统的,可以参考此方案。