[TOC]
1. 数仓作用
数据仓库最主要的工作是从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是 ETL(抽取Extra, 转化 Transfer, 装载 Load)的过程
2. 数据仓库特点
2.1 面向主题
是企业系统信息中的数据综合、归类并进行分析的一个抽象,对应企业中某一个宏观分析领域所涉及的分析对象。
比如购物是一个主题,那么购物里面包含用户、订单、支付、物流等数据综合,对这些数据要进行归类并分析,分析这个对象数据的一个完整性、一致性的描述,能完整、统一的划分对象所设计的各项数据。
如果此时要统计一个用户从浏览到支付完成的时间时,在购物主题中缺少了支付数据或订单数据,那么这个对象数据的完整性和一致性就可能无法保证了。
2.2 数据集成
数据仓库的数据是从原有分散的数据库中的数据抽取而来的。
操作型数据和支持决策分析型(DSS)数据差别甚大,这里需要做大量的数据清洗与数据整理的工作。
第一:每一个主题的源数据在原有分散数据库中的有许多重复和不一致,且不同数据库的数据是和不同的应用逻辑捆绑的。
第二:数据仓库中的综合性数据不能从原有的数据库系统直接得到,因此在数据进入数据仓库之前要进过统一和综合。(字段同名异意,异名同义,长度等)
2.3 不可更新
数据仓库的数据主要是提供决策分析用,设计的数据主要是数据查询,一般情况下不做修改,这些数据反映的是一段较长时间内历史数据的内容,有一块修改了影响的是整个历史数据的过程数据。
数据仓库的查询量往往很大,所以对数据查询提出了更高的要求,要求采用各种复杂的索引技术,并对数据查询的界面友好性和数据凸显性提出更高的要求。
2.4 随时间不断变化
数据仓库中的数据不可更新是针对应用来说,从数据的进入到删除的整个生命周期中,数据仓库的数据是永远不变的。
数据仓库的数据是随着时间变化而不断增加新的数据。
数据仓库随着时间变化不断删去久的数据内容,数据仓库的数据也有时限的,数据库的数据时限一般是60 ~ 90天,而数据仓库的数据一般是5年~10年。
数据仓库中包含大量的综合性数据,这些数据很多是跟时间有关的,这些数据特征都包含时间项,以标明数据的历史时期。
总结:数据仓库和数据库的区别
数据库的操作:一般称为联机事务处理OLTP(On-Line Transaction Processing),是针对具体的业务在数据库中的联机操作,具有数据量较少的特点,通常对少量的数据记录进行查询、修改。
数据仓库的操作:一般称为联机分析处理OLAP(On-Line Analytical Processing),是针对某些主题(综合数据)的历史数据进行分析,支持管理决策。
个人理解.数据库是给程序员或者说程序使用的.数仓面向的对象应该是业务人员.他们的关联应该是数据库的数据经过加工处理整理成业务数据存到数仓.
3. Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询
注意: 3. Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询 是csdn上Doris专栏的文章,本人和小伙伴在按照此文章搭建时,遇到了一些坑,因此把文章全部copy过来并做一些自己的笔记(3中的所有以 '笔记:' 开始,以'--------'结尾的内容是我个人的一些记录).
1.概览
这篇教程将展示如何使用 Flink CDC + Iceberg + Doris 构建实时湖仓一体的联邦查询分析,Doris 1.1版本提供了Iceberg的支持,本文主要展示Doris和Iceberg怎么使用,同时本教程整个环境是都基于伪分布式环境搭建,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。
1.1 软件环境
本教程的演示环境如下:
Centos7
Apahce doris 1.1
Hadoop 3.3.3
hive 3.1.3
Flink 1.14.4
flink-sql-connector-mysql-cdc-2.2.1
Apache Iceber 0.13.2
JDK 1.8.0_311
MySQL 8.0.29
wget https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
wget https://dlcdn.apache.org/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.12.tgz
wget https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime-1.14/0.13.2/iceberg-flink-runtime-1.14-0.13.2.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar笔记:
下载慢的可以使用清华大学的镜像网站:地址链接
文章中flink14的下载地址已经失效,flink14版本下载地址:地址链接
--------
1.2 系统架构
我们整理架构图如下
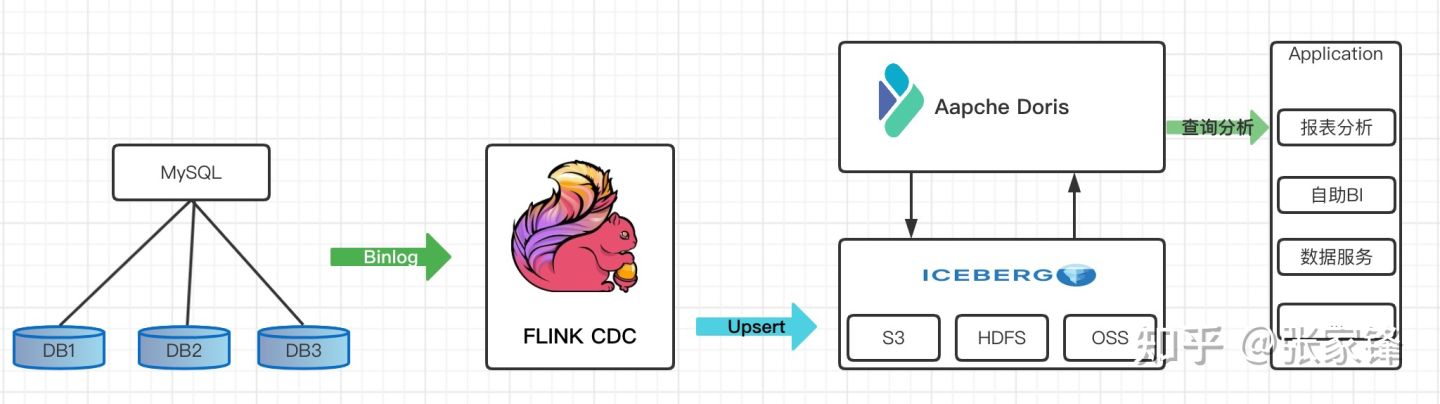
首先我们从Mysql数据中使用Flink 通过 Binlog完成数据的实时采集
然后再Flink 中创建 Iceberg 表,Iceberg的元数据保存在hive里
最后我们在Doris中创建Iceberg外表
在通过Doris 统一查询入口完成对Iceberg里的数据进行查询分析,供前端应用调用,这里iceberg外表的数据可以和Doris内部数据或者Doris其他外部数据源的数据进行关联查询分析
Doris湖仓一体的联邦查询架构如下:
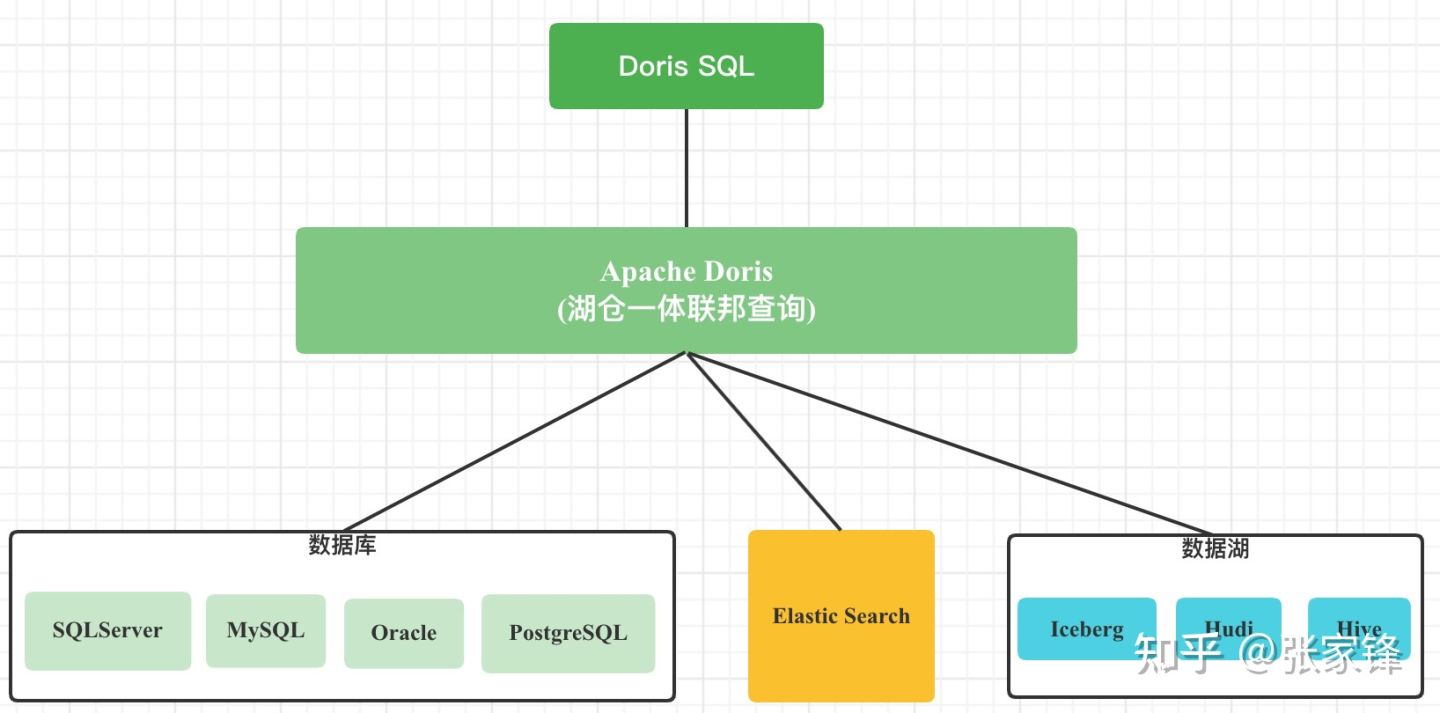
Doris 通过 ODBC 方式支持:MySQL,Postgresql,Oracle ,SQLServer
同时支持 Elasticsearch 外表
1.0版本支持Hive外表
1.1版本支持Iceberg外表
1.2版本支持Hudi 外表
笔记:
以上说了那么多软件,各个软件是做什么的,他们之间的联系是什么?
hadoop
Hive
hive是Hadoop的客户端,启动hive前必须启动hadoop,同时hive的元数据存储在mysql中,是由于hive自带的derby数据库不支持多客户端访问.
Flink
官网定义:Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
从Mysql数据中使用Flink 通过 Binlog完成数据的实时采
--------
2. 环境安装部署
2.1 安装Hadoop、Hive
tar zxvf hadoop-3.3.3.tar.gz
tar zxvf apache-hive-3.1.3-bin.tar.gz配置系统环境变量
export HADOOP_HOME=/data/hadoop-3.3.3
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HIVE_HOME=/data/hive-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin:$HIVE_HOME/conf2.2 配置hdfs
2.2.1 core-site.xml
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>2.2.2 hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hdfs/datanode</value>
</property>
</configuration>2.2.3 修改Hadoop启动脚本
sbin/start-dfs.sh
sbin/stop-dfs.sh
在文件开始加上下面的内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootsbin/start-yarn.sh
sbin/stop-yarn.sh
在文件开始加上下面的内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root2.3 配置yarn
这里我改变了Yarn的一些端口,因为我是单机环境和Doris 的一些端口冲突。你可以不启动yarn
vi etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>jiafeng-test:50056</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>jiafeng-test:50057</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>jiafeng-test:50058</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>jiafeng-test:50059</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>jiafeng-test:9090</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:50062</value>
</property>vi etc/hadoop/mapred-site.xm
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>50061</value>
</property>2.2.4 启动hadoop
sbin/start-all.sh笔记
我在启动时遇到了 http://localhost:50070 (HDFS的页面) 无法访问的问题,改成 http://localhost:9870 (三版本地址)后依然不行,执行jps命令后发现启动的项目不完整,少了nameNode,百度上说是要关闭防火墙,但是我防火墙已关闭后还是没有解决.

后来看到有人说时 namenode需要格式化,执行 hadoop namenode -format 后解决问题
--------
2.4 配置Hive
2.4.1 创建hdfs目录
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir /tmp
hdfs dfs -chmod g+w /user/hive/warehouse
hdfs dfs -chmod g+w /tmp2.4.2 配置hive-site.xml
此文件在hive文件夹下的conf文件夹中,有一个hive-default.xml.template文件,拷贝出来使用,执行下面命令
cp $HIVE_HOME/conf/hive-default.xml.template $HIVE_HOME/conf/hive-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MyNewPass4!</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value/>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>笔记:
这个文件是在配置数据库,所以在此之前要把mysql数据库配好,包括用户名密码等等要和配置中的信息一一对应.
2.4.3 配置 hive-env.sh
执行命令
cp $HIVE_HOME/conf/hive-env.sh.template $HIVE_HOME/conf/hive-env.sh加入以下内容
# hadoop的解压路径
HADOOP_HOME=/data/hadoop-3.3.3 2.4.4 hive元数据初始化
schematool -initSchema -dbType mysql笔记:
初始化的时候报错:
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
Underlying cause: java.lang.ClassNotFoundException : com.mysql.jdbc.Driver很明显,驱动没配,需要把链接mysql的驱动拷贝到hive安装目录的lib目录下.
MySql驱动网盘下载地址 提取码:xjye
2.4.5 启动hive metaservice
后台运行
nohup bin/hive --service metaservice 1>/dev/null 2>&1 &笔记:
这里启动命令是不是写错了,感觉应该是
nohup bin/hive --service metastore 1>/dev/null 2>&1 &验证
lsof -i:9083
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 20700 root 567u IPv6 54605348 0t0 TCP *:emc-pp-mgmtsvc (LISTEN)2.5 安装MySQL
2.5.1 创建MySQL数据库表并初始化数据
CREATE DATABASE demo;
USE demo;
CREATE TABLE userinfo (
id int NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255),
PRIMARY KEY (`id`)
)ENGINE=InnoDB ;
INSERT INTO userinfo VALUES (10001,'user_110','Shanghai','13347420870', NULL);
INSERT INTO userinfo VALUES (10002,'user_111','xian','13347420870', NULL);
INSERT INTO userinfo VALUES (10003,'user_112','beijing','13347420870', NULL);
INSERT INTO userinfo VALUES (10004,'user_113','shenzheng','13347420870', NULL);
INSERT INTO userinfo VALUES (10005,'user_114','hangzhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10006,'user_115','guizhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10007,'user_116','chengdu','13347420870', NULL);
INSERT INTO userinfo VALUES (10008,'user_117','guangzhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10009,'user_118','xian','13347420870', NULL);2.6 安装 Flink
tar zxvf flink-1.14.4-bin-scala_2.12.tgz然后需要将下面的依赖拷贝到Flink安装目录下的lib目录下,具体的依赖的lib文件如下:
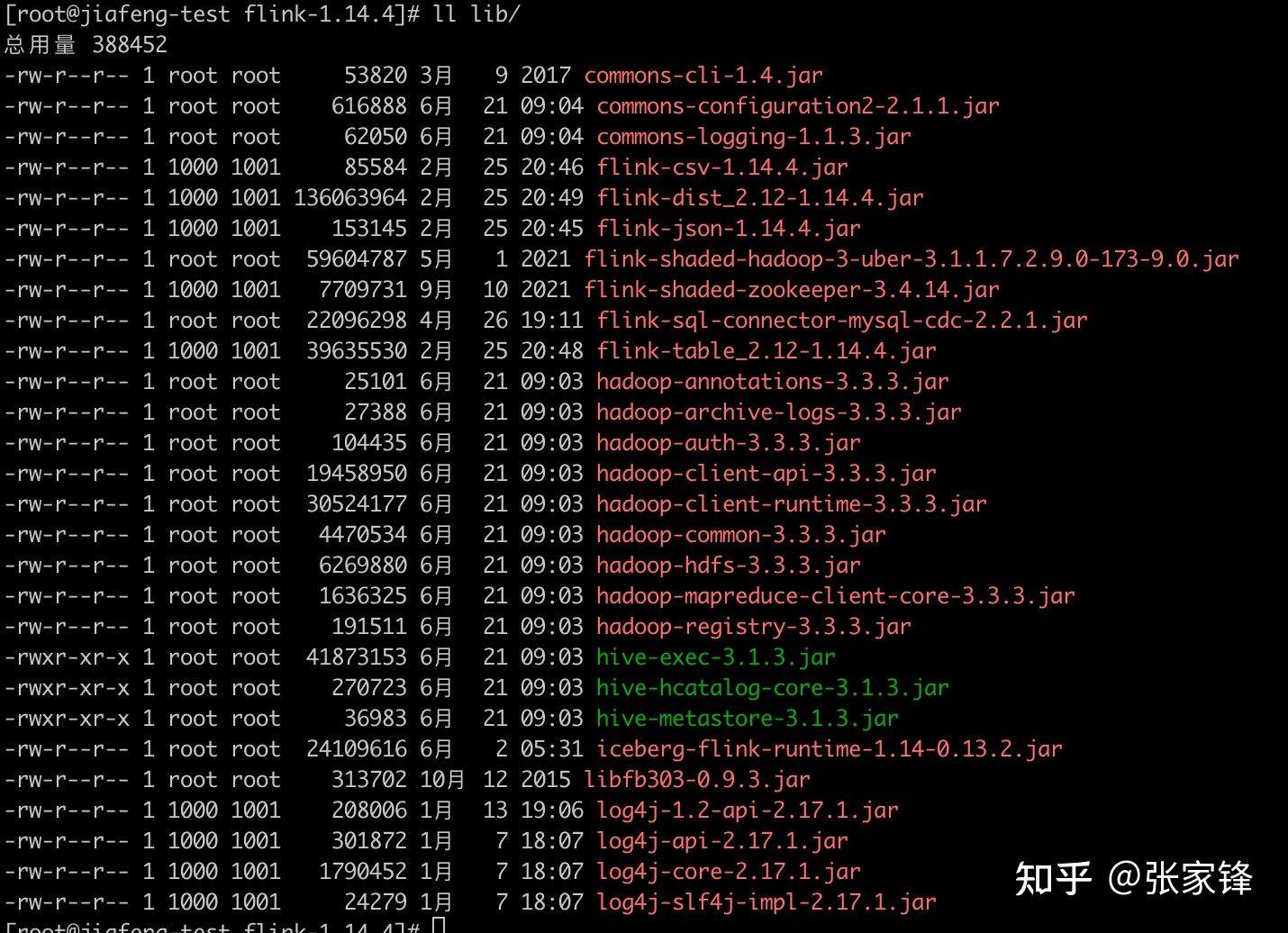
下面将几个Hadoop和Flink里没有的依赖下载地址放在下面
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.1/flink-sql-connector-mysql-cdc-2.2.1.jar
wget https://repo1.maven.org/maven2/org/apache/thrift/libfb303/0.9.3/libfb303-0.9.3.jar
wget https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime-1.14/0.13.2/iceberg-flink-runtime-1.14-0.13.2.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar其他的:
hadoop-3.3.3/share/hadoop/common/lib/commons-configuration2-2.1.1.jar
hadoop-3.3.3/share/hadoop/common/lib/commons-logging-1.1.3.jar
hadoop-3.3.3/share/hadoop/tools/lib/hadoop-archive-logs-3.3.3.jar
hadoop-3.3.3/share/hadoop/common/lib/hadoop-auth-3.3.3.jar
hadoop-3.3.3/share/hadoop/common/lib/hadoop-annotations-3.3.3.jar
hadoop-3.3.3/share/hadoop/common/hadoop-common-3.3.3.jar
adoop-3.3.3/share/hadoop/hdfs/hadoop-hdfs-3.3.3.jar
hadoop-3.3.3/share/hadoop/client/hadoop-client-api-3.3.3.jar
hive-3.1.3/lib/hive-exec-3.1.3.jar
hive-3.1.3/lib/hive-metastore-3.1.3.jar
hive-3.1.3/lib/hive-hcatalog-core-3.1.3.jar2.6.1 启动Flink
bin/start-cluster.sh 启动后的界面如下:
2.6.2 进入 Flink SQL Client
bin/sql-client.sh embedded 笔记:
执行bin/sql-client.sh embedded命令时报错,
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.commons.cli.Option.builder(Ljava/lang/String;)Lorg/apache/commons/cli/Option$Builder;
at org.apache.flink.table.client.cli.CliOptionsParser.<clinit>(CliOptionsParser.java:50)
at org.apache.flink.table.client.SqlClient.startClient(SqlClient.java:181)
at org.apache.flink.table.client.SqlClient.main(SqlClient.java:161)为啥,报错提示提到了 commons/cli,其实是因为这个包版本太低,hadoop那边拷贝过来的是1.2的,需要使用的是1.4的.
commoon-cli-1.4.jar的下载地址:链接
顺便说一下flink的关闭命令:$ ./bin/stop-cluster.sh
--------
搞定后出现如下界面:
开启 checkpoint,每隔3秒做一次 checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 来让 Iceberg 可以提交事务。 并且,mysql-cdc 在 binlog 读取阶段开始前,需要等待一个完整的 checkpoint 来避免 binlog 记录乱序的情况。
注意:
这里是演示环境,checkpoint的间隔设置比较短,线上使用,建议设置为3-5分钟一次checkpoint。Flink SQL> SET execution.checkpointing.interval = 3s;
[INFO] Session property has been set.2.6.3 创建Iceberg Catalog
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://localhost:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://localhost:8020/user/hive/warehouse'
);查看catalog
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| hive_catalog |
+-----------------+
2 rows in set2.6.4 创建 Mysql CDC 表
CREATE TABLE user_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'MyNewPass4!',
'database-name' = 'demo',
'table-name' = 'userinfo'
);查询CDC表:
select * from user_source;
2.6.5 创建Iceberg表
---查看catalog
show catalogs;
---使用catalog
use catalog hive_catalog;
--创建数据库
CREATE DATABASE iceberg_hive;
--使用数据库
use iceberg_hive;笔记:
这里在CREATE DATABASE iceberg_hive; 时报错:
Flink SQL> create database iceberg_hive;
[ERROR] Could not execute SQL statement. Reason:
org.apache.hadoop.hive.metastore.api.MetaException: Got exception: java.net.ConnectException Call From honor-virtual-machine/127.0.1.1 to localhost:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused这就很坑,问题范围太广,都不知道是环境的问题还是软件配置的问题.不过经过在下的一番深思熟虑还是找到了问题所在.
报错在说 localhost:8020拒绝连接,但是我看文章从未配置过8020,那么这个8020到底是什么呢?看下面的这篇文章:链接.看完之后明白,原来8020端口在hadoop1.x中默认承担着namenode 和 datanode之间的心跳通信,且也兼顾着FileSystem默认的端口号(就是hdfs客户端访问hdfs集群的RPC通信端口),
但是在hadoop2.x中,8020只承担了namenode 和 datanode之间的心跳通信,当然这些端口的设置是指的默认设置。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>再往上翻一下作者的文章,果然,这小子把这个默认配置改成了 9000.坑啊.所以把9000那里的配置改成8020或者把CREATE CATALOG hive_catalog中的warehouse改成warehouse'='hdfs://localhost:9000/user/hive/warehouse
--------
2.6.5.1 创建表
CREATE TABLE all_users_info (
database_name STRING,
table_name STRING,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED
) WITH (
'catalog-type'='hive'
);从CDC表里插入数据到Iceberg表里
use catalog default_catalog;
insert into hive_catalog.iceberg_hive.all_users_info select * from user_source;在web界面可以看到任务的运行情况
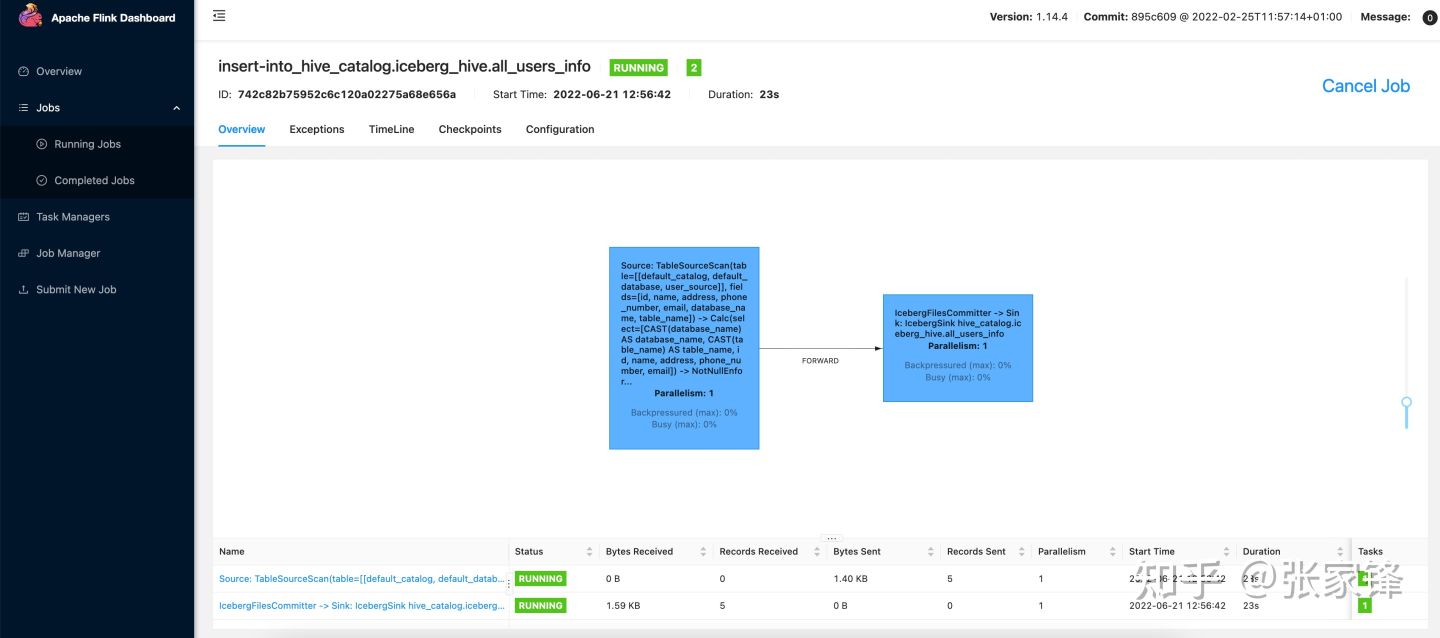
然后停掉任务,我们去查询iceberg表
select * from hive_catalog.iceberg_hive.all_users_info可以看到下面的结果

我们去hdfs上可以看到hive目录下的数据及对应的元数据
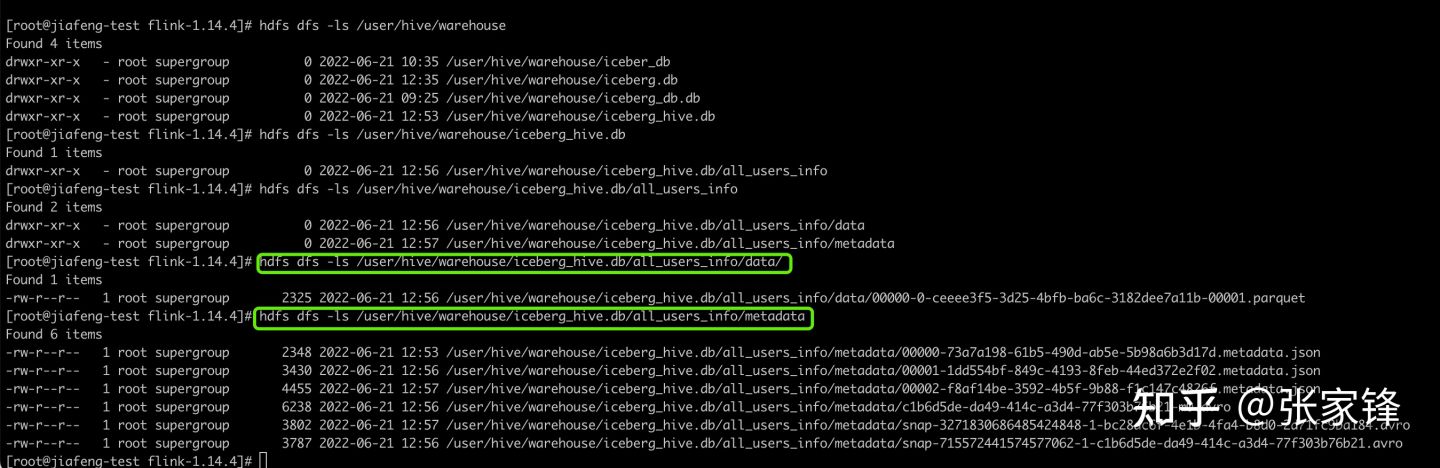
笔记:
至此我们完成了从mysql数据库取数据并使用逻辑处理软件获取到数据的操作.梳理一下操作过程:
创建
Iceberg Catalog,通过CataLog的方式将mysql数据库服务器中的demo库信息(flink的catalog的具体每个参数还要取官网研究下,本文用的的几个大致有所猜测,在此备注下)CREATE CATALOG hive_catalog WITH ( 'type'='iceberg', (数据湖表格式) 'catalog-type'='hive',(catalog映射类型) 'uri'='thrift://localhost:9083',(hive的metastore启动后的地址) 'clients'='5', 'property-version'='1', 'warehouse'='hdfs://localhost:9000/user/hive/warehouse'(2.4.1中创建的hdfs目录,端口号为core-site.xml中fs.defaultFS配置的) );建立好catalog映射后,建立 mysql数据库中userinfo 表的映射(即2.6.4 创建 Mysql CDC 表)的操作.
在Iceberg Catalog下创建名称为 iceberg_hive 的数据库,在iceberg_hive数据库中 插入 2步骤中 Mysql CDC 表的内容.
--------
2.6.5.2 创建表
我们也可以通过Hive建好Iceberg表,然后通过Flink将数据插入到表里
下载Iceberg Hive运行依赖
wget https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-hive-runtime/0.13.2/iceberg-hive-runtime-0.13.2.jar在hive shell下执行:
SET engine.hive.enabled=true;
SET iceberg.engine.hive.enabled=true;
SET iceberg.mr.catalog=hive;
add jar /path/to/iiceberg-hive-runtime-0.13.2.jar;创建表
CREATE EXTERNAL TABLE iceberg_hive(
`id` int,
`name` string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://localhost:8020/user/hive/warehouse/iceber_db/iceberg_hive'
TBLPROPERTIES (
'iceberg.mr.catalog'='hadoop',
'iceberg.mr.catalog.hadoop.warehouse.location'='hdfs://localhost:8020/user/hive/warehouse/iceber_db/iceberg_hive'
);然后再Flink SQL Client下执行下面语句将数据插入到Iceber表里
INSERT INTO hive_catalog.iceberg_hive.iceberg_hive values(2, 'c');
INSERT INTO hive_catalog.iceberg_hive.iceberg_hive values(3, 'zhangfeng');查询这个表
select * from hive_catalog.iceberg_hive.iceberg_hive可以看到下面的结果

3. Doris 查询 Iceberg
Apache Doris 提供了 Doris 直接访问 Iceberg 外部表的能力,外部表省去了繁琐的数据导入工作,并借助 Doris 本身的 OLAP 的能力来解决 Iceberg 表的数据分析问题:
支持 Iceberg 数据源接入Doris
支持 Doris 与 Iceberg 数据源中的表联合查询,进行更加复杂的分析操作
3.1安装Doris
这里我们不在详细讲解Doris的安装,如果你不知道怎么安装Doris请参照官方文档: 快速入门
笔记:
作者提供的安装路径已经失效,以下是新的地址.同时doris1.1.0的be启动有问题,git的issue上推荐使用1.1.3.我在部署中使用的也是1.1.3.
--------
3.2 创建Iceberg外表
CREATE TABLE `all_users_info`
ENGINE = ICEBERG
PROPERTIES (
"iceberg.database" = "iceberg_hive",
"iceberg.table" = "all_users_info",
"iceberg.hive.metastore.uris" = "thrift://localhost:9083",
"iceberg.catalog.type" = "HIVE_CATALOG"
);参数说明:
ENGINE 需要指定为 ICEBERG
PROPERTIES 属性:
iceberg.hive.metastore.uris:Hive Metastore 服务地址
iceberg.database:挂载 Iceberg 对应的数据库名
iceberg.table:挂载 Iceberg 对应的表名,挂载 Iceberg database 时无需指定。
iceberg.catalog.type:Iceberg 中使用的 catalog 方式,默认为 HIVE_CATALOG,当前仅支持该
方式,后续会支持更多的 Iceberg catalog 接入方式。
mysql> CREATE TABLE `all_users_info`
-> ENGINE = ICEBERG
-> PROPERTIES (
-> "iceberg.database" = "iceberg_hive",
-> "iceberg.table" = "all_users_info",
-> "iceberg.hive.metastore.uris" = "thrift://localhost:9083",
-> "iceberg.catalog.type" = "HIVE_CATALOG"
-> );
Query OK, 0 rows affected (0.23 sec)
mysql> select * from all_users_info;
+---------------+------------+-------+----------+-----------+--------------+-------+
| database_name | table_name | id | name | address | phone_number | email |
+---------------+------------+-------+----------+-----------+--------------+-------+
| demo | userinfo | 10004 | user_113 | shenzheng | 13347420870 | NULL |
| demo | userinfo | 10005 | user_114 | hangzhou | 13347420870 | NULL |
| demo | userinfo | 10002 | user_111 | xian | 13347420870 | NULL |
| demo | userinfo | 10003 | user_112 | beijing | 13347420870 | NULL |
| demo | userinfo | 10001 | user_110 | Shanghai | 13347420870 | NULL |
| demo | userinfo | 10008 | user_117 | guangzhou | 13347420870 | NULL |
| demo | userinfo | 10009 | user_118 | xian | 13347420870 | NULL |
| demo | userinfo | 10006 | user_115 | guizhou | 13347420870 | NULL |
| demo | userinfo | 10007 | user_116 | chengdu | 13347420870 | NULL |
+---------------+------------+-------+----------+-----------+--------------+-------+
9 rows in set (0.18 sec)3.3 同步挂在
当 Iceberg 表 Schema 发生变更时,可以通过 REFRESH 命令手动同步,该命令会将 Doris 中的 Iceberg 外表删除重建。
-- 同步 Iceberg 表
REFRESH TABLE t_iceberg;
-- 同步 Iceberg 数据库
REFRESH DATABASE iceberg_test_db;3.4 Doris 和 Iceberg 数据类型对应关系
支持的 Iceberg 列类型与 Doris 对应关系如下表:
3.5 注意事项
Iceberg 表 Schema 变更不会自动同步,需要在 Doris 中通过
REFRESH命令同步 Iceberg 外表或数据库。当前默认支持的 Iceberg 版本为 0.12.0,0.13.x,未在其他版本进行测试。后续后支持更多版本。
3.6 Doris FE 配置
下面几个配置属于 Iceberg 外表系统级别的配置,可以通过修改 fe.conf 来配置,也可以通过 ADMIN SET CONFIG 来配置。
iceberg_table_creation_strict_mode
创建 Iceberg 表默认开启 strict mode。 strict mode 是指对 Iceberg 表的列类型进行严格过滤,如果有 Doris 目前不支持的数据类型,则创建外表失败。
iceberg_table_creation_interval_second
自动创建 Iceberg 表的后台任务执行间隔,默认为 10s。
max_iceberg_table_creation_record_size
Iceberg 表创建记录保留的最大值,默认为 2000. 仅针对创建 Iceberg 数据库记录。
4. 总结
这里Doris On Iceberg我们只演示了Iceberg单表的查询,你还可以联合Doris的表,或者其他的ODBC外表,Hive外表,ES外表等进行联合查询分析,通过Doris对外提供统一的查询分析入口。
自此我们完整从搭建Hadoop,hive、flink 、Mysql、Doris 及Doris On Iceberg的使用全部介绍完了,Doris朝着数据仓库和数据融合的架构演进,支持湖仓一体的联邦查询,给我们的开发带来更多的便利,更高效的开发,省去了很多数据同步的繁琐工作,快快来体验吧。
声明:Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询 基本按照博主「hf200012」的原创文章,只是补充了搭建过程中博主没有提到的一些坑.
酷酷酷