背景
clickhouse在19年之前的版本都只能挂载单数据盘。单数据盘运维起来还是比较简单的,但是大规模生产部署后,这种弊端就很多
- 成本很高,利用率很低,数据被限制在单盘上,当存储资源不够,只能被动的扩单盘
- 不具备高可用的能力,单盘故障,整个集群就故障了,风险非常高
- 没有冷热数据的处理能力,性能会受较大影响。举个例子,我需要将热数据存储于SSD盘,而不怎么使用的数据存储于HDD盘,这时候多磁盘分卷部署的能力就体现出来了
在19年底的版本里,clickhouse提供了分卷的策略能力,使集群具备分层存储,能够挂多个数据盘,可用性和经济性大大提升
clickhouse多卷架构
在了解如何使用之前,先简单看下clickhouse多卷的工作原理
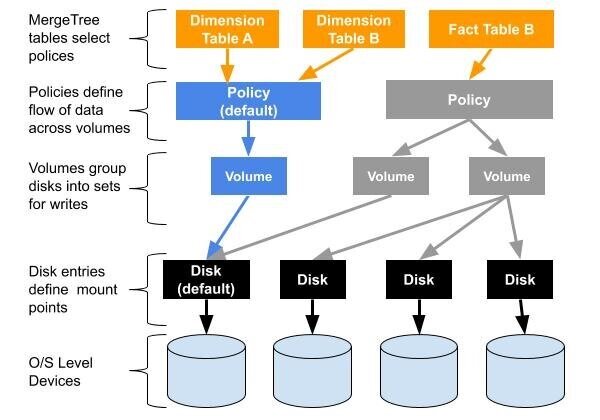
每个 MergeTree 表都与一个存储策略相关联。策略只是编写 MergeTree 表数据的规则。它们将磁盘分组为一个或多个卷。它们还定义了每个卷内磁盘的写入顺序以及数据在多个卷之间移动的方式。
存储策略向后兼容旧表。ClickHouse 始终有一个名为“default”的磁盘,它指向 config.xml 中的数据目录路径。还有一个相应的策略称为“默认”。如果 MergeTree 表没有存储策略,ClickHouse 将使用默认策略并写入默认磁盘。
如何配置分卷策略
clickhouse的安装部署我们略过,以下的介绍都是在集群模式下
设置数据盘
首先我们对其虚拟机,挂载多个数据盘。我这边是通过xfs格式化并挂载的磁盘,最终展现如下,我这边每个机器挂了8个5T的数据盘
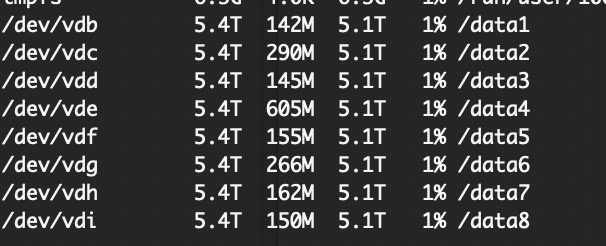
有了盘了,那么下一步,我们要将盘让clickhouse感知,并能将数据写入进去,下面我们看下咋弄
设置config.xml
- 在config.xml 加上这一段
<storage_configuration>
<disks>
<!--
default disk is special, it always
exists even if not explicitly
configured here, but you can't change
it's path here (you should use <path>
on top level config instead)
-->
<default>
<!--
You can reserve some amount of free space
on any disk (including default) by adding
keep_free_space_bytes tag
-->
<keep_free_space_bytes>1024</keep_free_space_bytes>
</default>
<ch1><path>/data1/</path></ch1>
<ch2><path>/data2/</path></ch2>
<ch3><path>/data3/</path></ch3>
<ch4><path>/data4/</path></ch4>
<ch5><path>/data5/</path></ch5>
<ch6><path>/data6/</path></ch6>
<ch7><path>/data7/</path></ch7>
<ch8><path>/data8/</path></ch8>
</disks>
<policies>
<log_jbod>
<volumes>
<log_volume>
<disk>ch1</disk>
<disk>ch2</disk>
<disk>ch3</disk>
<disk>ch4</disk>
<disk>ch5</disk>
<disk>ch6</disk>
<disk>ch7</disk>
<disk>ch8</disk>
</log_volume>
</volumes>
</log_jbod>
</policies>
</storage_configuration>
storage_configuration 标签,就是我们的主体了
disks: 具体的磁盘位置
policies: 我们的策略,这个地方留意我自定义的标签log_jbod 下面会讲
好,我们先将config.xml改掉,然后重启server
- 那么怎么判定到clickhouse有没有感知到磁盘呢,我们执行以下sql语句
SELECT
name,
path,
formatReadableSize(free_space) AS free,
formatReadableSize(total_space) AS total,
formatReadableSize(keep_free_space) AS reserved
FROM system.disks
结果如下
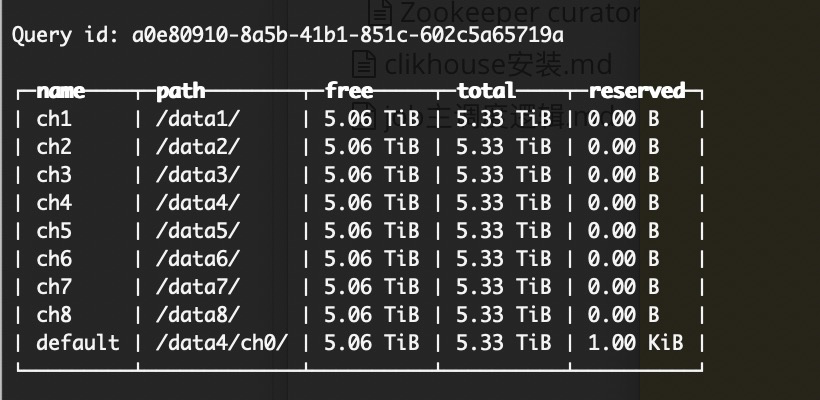
大家看到的数据盘是能被clickhouse感知的,包括我设置的default盘
感知到是不是就结束,并没有,看以下sql
SELECT
name,
data_paths
FROM system.tables
WHERE name = 'soa_detail'
我创建了log表,想看下他对应的存储目录,以下是结果

我们看到他落到了默认的default目录下,这不是我想要的,那他为什么这样呢
这是需要创建表的时候就要设置好分卷策略,clickhouse是分卷的维度是控制到表的,哪个表走哪个磁盘,这都可以控制,不单独设置的话,默认的都走default的设置
-
创建表对应到分卷上
我们在创建表的语句后面加上这么一句话
SETTINGS storage_policy = 'log_jbod'
大家再回到第一点,我们设置config的时候,设置了一个自定义标签log_jbod,他的作用就体现在这
我们再来看下当前这张表的存储目录

我们看到当前,data_paths的数据路径已经是我设置的8个磁盘目录了,这表示数据分卷已经真正作用到clickhouse中了
总结
以上就是数据分卷的一个小的总结,数据分卷还可以设置冷热分离,并能针对不同的数据盘设置不同的merge_tree的策略,有时间我们再讨论