通过前几篇章节,初步认识了通过 RestTemplate 调用微服务拆分的服务的 rest 请求,进一步引入了通过 Eureka 来实现服务注册于发现(此部分的拓展内容其实还有很多,牵扯到自定义元数据及 Eureka 的自我保护等)。
那么问题来了,在实际的场景中我们会遇到很多服务端其实是存在多个副本以实现高可用,那么客户端的请求是如何做分发控制的呢?当然,朋友你肯定第一个想到的是老毛子搞的 nginx。Nice!!nginx 确实很强大,基于 nginx 我们能做很多事情【后续我也会对 nginx 做进一步的分享:)】。在 Spring Cloud 生态圈,其实大佬们早已准备好了开箱即用的组件,就是今天的主角:Riboon。
Eureka 与 Ribbon 配合的架构图
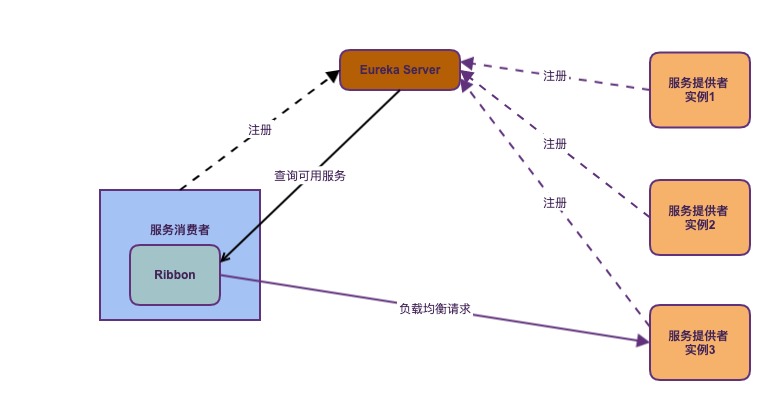
服务消费者
microservice-consumer-movie-ribbon
将之前的 microservice-consumedr-movie 整合 Ribbon 改造下。
- pom 文件
由于此微服务还是 Eureka 的 Client 端,所以依赖中还是会存在 eureka client 的依赖,同时加入新的依赖 netflix-ribbon
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.kirago.sc</groupId>
<artifactId>microserver-consumer-movie-ribbon</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>microserver-consumer-movie-ribbon</name>
<description>microserver-consumer-movie-ribbon project for Spring cloud</description>
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.SR1</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--<dependency>-->
<!--<groupId>org.springframework.boot</groupId>-->
<!--<artifactId>spring-boot-starter-logging</artifactId>-->
<!--</dependency>-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
- 为 RestTemplate 添加 @LoadBalanced 的注解进行声明。
此部分我是通过 @Configuration 注解 后加入 @Bean 注解,来告知应用生成这个 Bean。
此处有个知识点,可以拓展下 @Configuration 的具体作用:
- 在实际的项目开发中,我引用的类可能不在当前包中那么如何处理?
- 还有我们很多时候会发现一个类被 @Configuration 注解了实际上类的内部为空,那么这个 @Configuration 存在的意思是啥,为啥需要它?
以上都是需要掌握的。
package com.kirago.sc.microserverconsumermovieribbon.config;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class RestTemplateCompoment {
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
服务生产者
microservice-priovider-user-ribbon
在完善此 demo 的时候由于是单机本地环境,所以我们需要通过对同一个应用启动应用多个端口来来实现生成多个实例来模拟多节点多副本的场景,我是通过 IDEA 中采用配置去实现的。
具体的实现方式参考 csdn 上的一篇文章,亲测有效。
此篇 服务消费者没啥改动,所以我就不贴示例代码了。
服务注册与发现
microservice-discovery-eureka
此服务也未作任何变动,所以此部分就不重复了。:)
验证
启动 microservice-discovery-eureka、microservice-consumer-movie-ribbon、microservice-discovery-eureka(我设置的副本数为2),成功运行的情况下去浏览 Eureka 服务的监控页面,会看到如下内容:
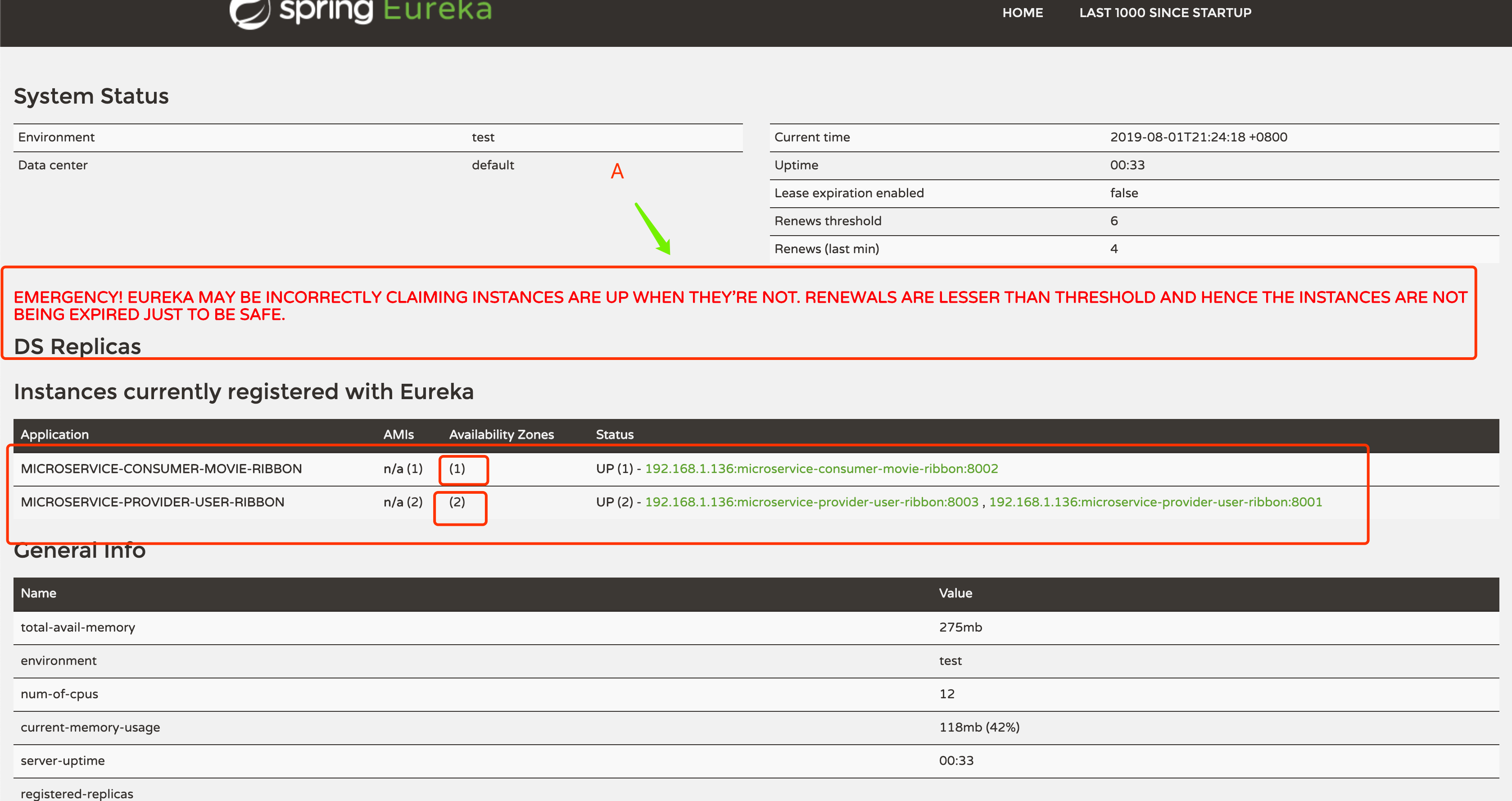
我们会发现服务生产者副本数为2,说明多副本服务创建成功了。
各位老铁应该注意到我特意标注了 A 点,这里就卖个关子,作为自己拓展思考,此处为啥会有红色字体的 Warnninng,以及这种展示是否是可控的,如果是可控的要做什么配置修改?:)
下面我们可以发送请求进一步验证下
- 对服务生产者直接请求:
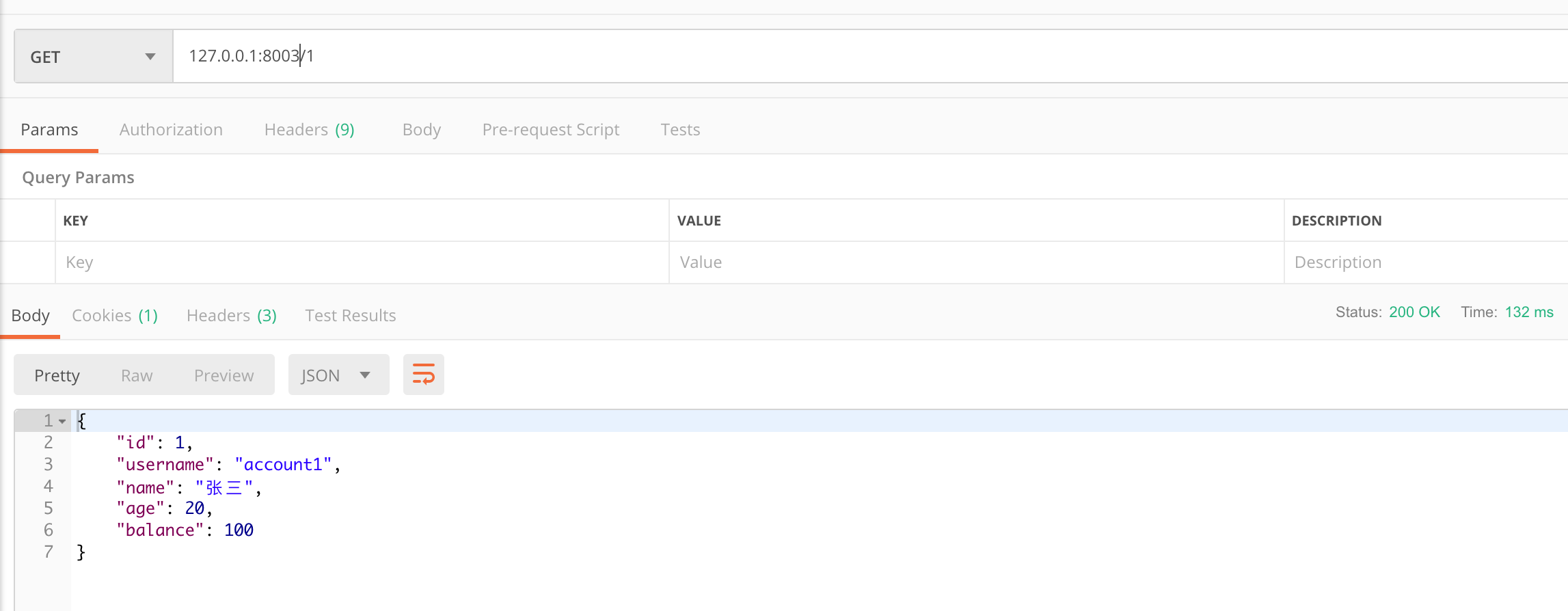
此处我故意请求的是我创建的服务生产者多副本实例2,验证下服务确实可用。
- 对服务消费者发送请求:
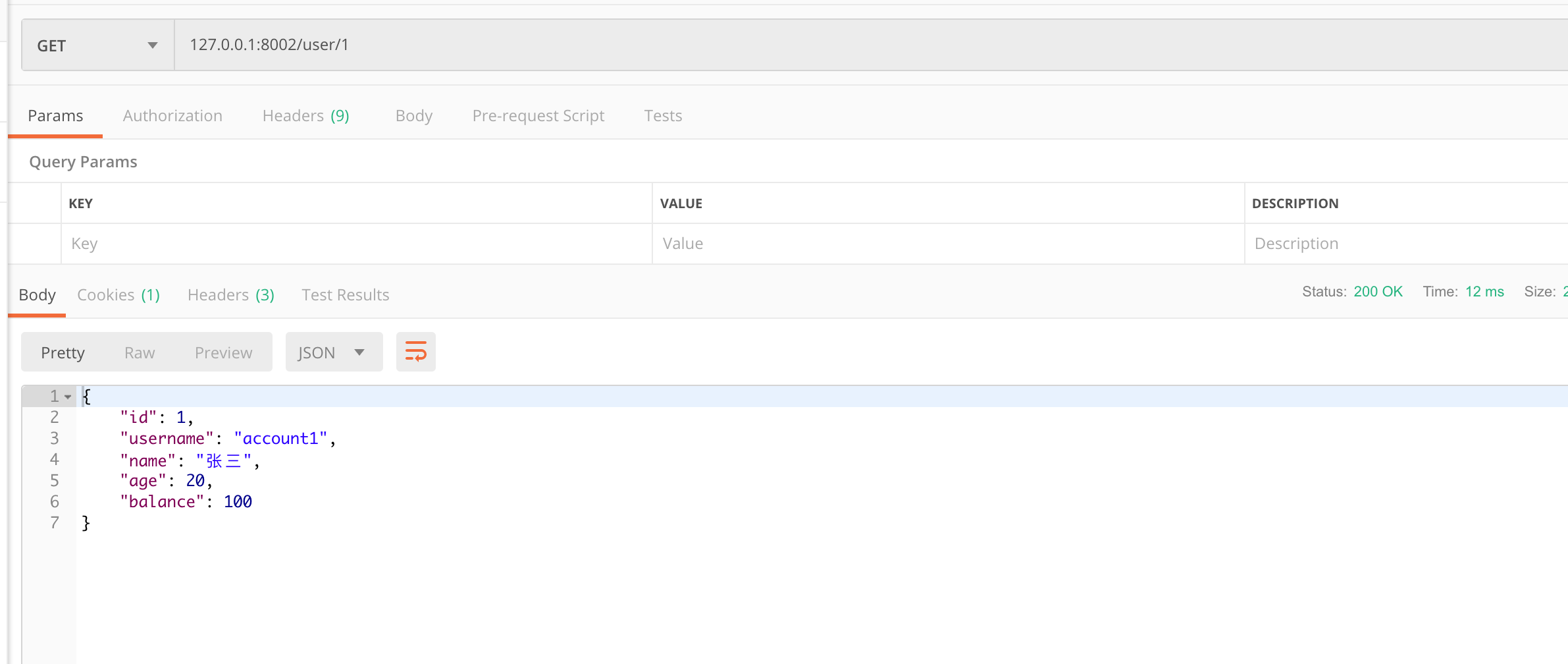
由此验证最终结果是保持一致的。
- 通过后台日志我们其实可以发现最终的请求最终落在那个服务生产者示例上:
此次通过服务消费者消费的服务是落在服务生产者多副本的实例1上。
多啰嗦几句
此偏章节为 Eureka 结合 Ribbon 实现负载均衡,在实际的生产项目中,我们的服务器会处理性能不一致,遵循“能者多劳”的原则,我们可能要适当的对负载分发有一定的可控机制,或者由于目前容器技术 docker 的新起,一台服务器我们会尽量的压榨资源,那么在部署架构上我们已经有了规划,那么对负载分发也要有一定的可控机制去实现,这些在实际的生产过程中我认为都是需要考虑的。
此章节示例代码:chapter3